

目次
無視するテキストを追加
テキスト無視ルールは、定義できる特定の条件に基づいて一部のテキストが翻訳されないようにします。.
これは通常、ウェブサイトの翻訳に最初に追加するルールで、製品名や会社名などを除外するために使用します。このルールを追加するには、 Linguise ダッシュボード > [ルール] > [新しいルールの追加] をクリックします。.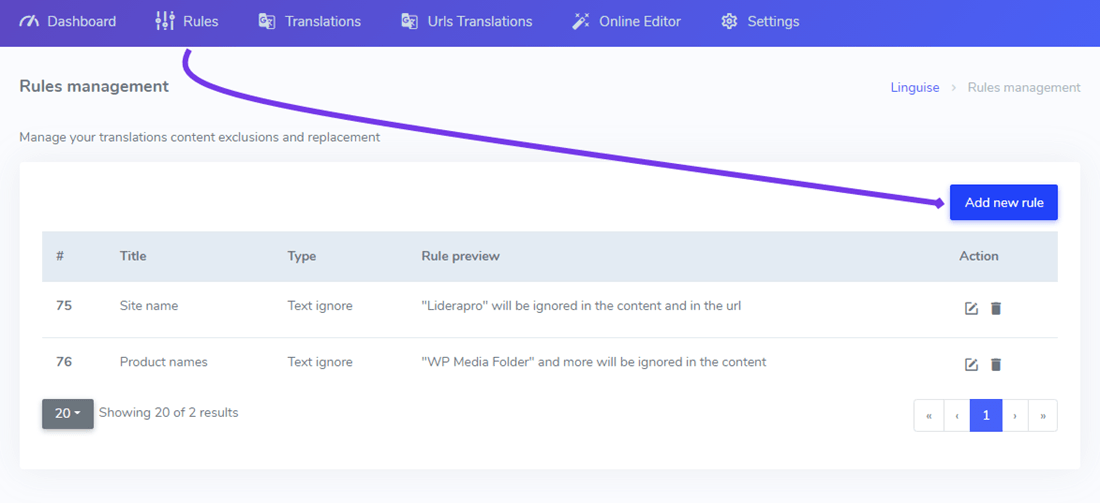
その後、主に以下のテキスト無視ルールの詳細を更新できるようになります。
- 除外したいテキスト
- テキスト除外の条件
- ルールのタイトル( Linguise ダッシュボードではあなただけに表示されます)
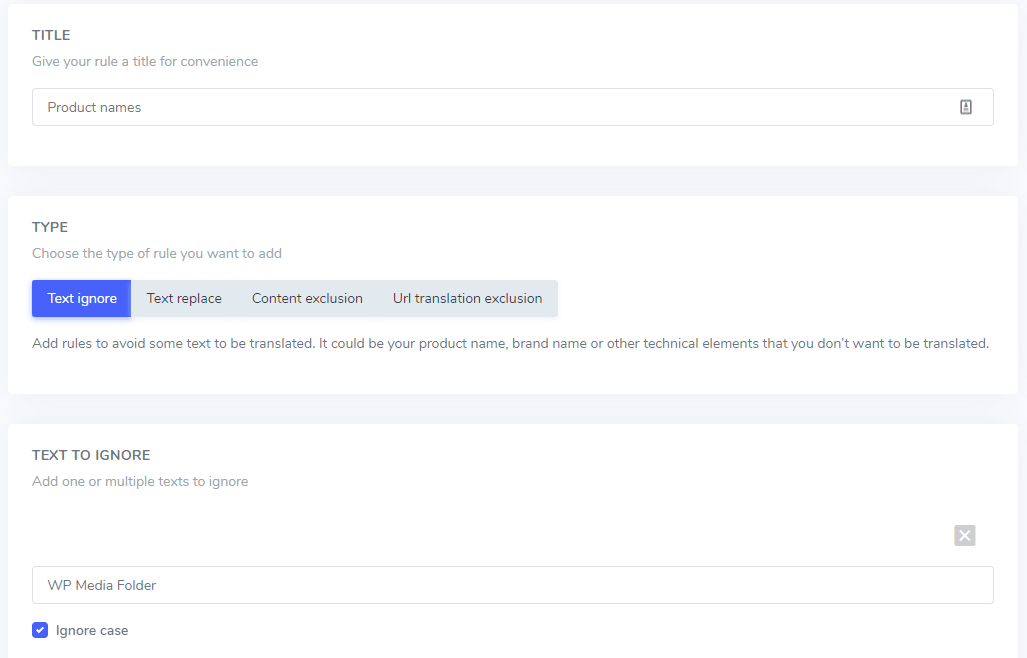
無視するテキスト フィールドでは、同じルールで除外する複数のテキスト式を追加できます。この例に従うと、複数のブランド名を除外する画面は次のようになります。
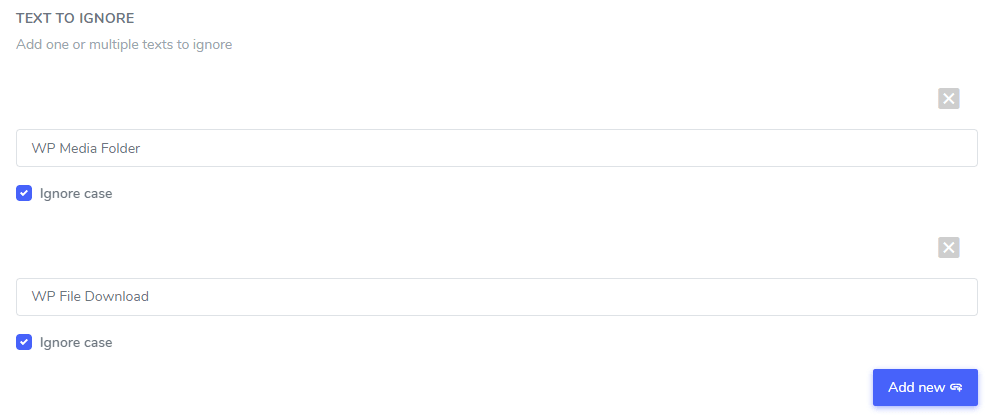
大文字小文字を区別しない設定: テキスト入力は大文字小文字を区別します。つまり、チェックボックス がオンになっている場合、 ルールは大文字 と小文字を同じものとして解釈します。翻訳除外の例: 大文字小文字を区別しない設定が有効になっている場合、「playerPrime」と「PrimeVideoVideoplayer」の両方が除外されます。
URLによるテキストを無視
翻訳から無視するテキストを設定したら、すべての Web サイト URL (すべての URL オプションを使用) または特定のページ URL のテキストを除外できます。.
- 元の URL / 翻訳された URL: 元の言語の特定の URL または翻訳された言語の特定の URL の翻訳テキストを無視します。
- ワイルドカード/正規表現: ワイルドカードまたは正規表現を使用して、特定の URL の翻訳テキストを無視します。
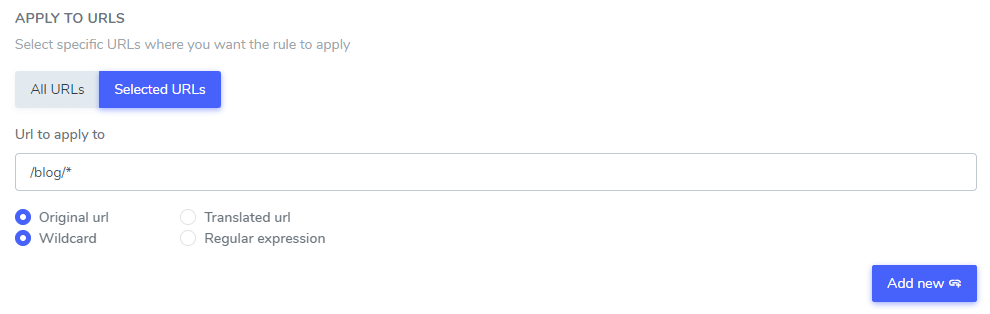
この例では、 「Netflix プレーヤー」、「PrimeVideo プレーヤー」、「YouTube プレーヤー」は、www.domain.com/blog/ で始まるすべての Web サイト URL の翻訳から除外されます。
たとえば、複数の翻訳言語の URL をカバーするために、複数の URL 条件を組み合わせることができます。.
正規表現パターンマッチング
正規表現( RegEx )を使用するには、構文と関連する概念をある程度理解する必要があります。正規表現では、URLと単語で異なる構文が使用されます。
ワイルドカードは理解しやすく、単純なタスクには使いやすいですが、RegEx はより高度で柔軟なパターン マッチング機能を提供します。.
正規表現の単語一致パターンの一般的な例を以下に示します。
- 「Light」で始まる単語に一致:
正規表現: Light\w
説明: 「Light」で始まり、その後に0個以上の単語文字(\w)が続く単語に一致します。これは、「Light」、「Lightbulb」、「Lightweight」などに一致します。 - 「Light」で終わる単語にマッチします:
正規表現: \w*Light
説明: 「Light」で終わり、その前に0個以上の単語文字が続く単語にマッチします。これは、「Sunlight」、「Daylight」、「Spotlight」などにマッチする可能性があります。 - 「Linguise」という単語全体に一致させる:
正規表現: \bLinguise\b
の文字のみで構成される文字列に一致しますLinguiseのような他の単語には一致せず LinguiseのみにLinguise。
正規表現の詳細については、こちらをご覧ください: https://www.regular-expressions.info/
この点についてご不明な点がある場合は、通常の使用においては正規表現よりもワイルドカードの使用をお勧めします。ご不明な点やご質問がございましたら、お問い合わせフォームからお気軽にご連絡ください。
言語別にテキストを無視
追加したテキストの除外は、特定の言語のみ、またはすべての言語で行うことができます。これは、複数の言語で同じ綴りを持つ単語であっても、1つの言語でのみ除外したい場合に非常に便利です。例えば、「ilimitados」という単語はポルトガル語でもスペイン語でも同じ綴りです。.
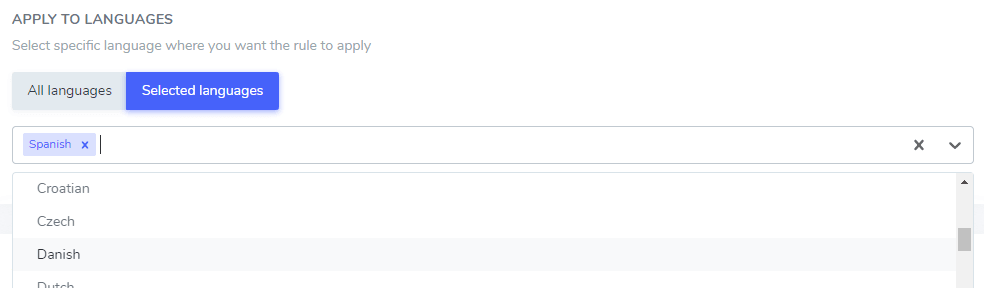
この例では、 「Netflixプレーヤー」、「PrimeVideoプレーヤー」、「YouTubeプレーヤー」は、スペイン語の翻訳でのみ除外されます。
HTMLコンテンツ内のテキストを無視する
追加したテキスト無視は、1つまたは複数のCSSセレクターを使用してHTMLコンテンツの一部から除外できます。ブラウザのコードインスペクターを使用して任意のCSSセレクターを取得し、以下のように追加してください。.
CSS セレクターを取得します。

ルール設定にこれを追加します:
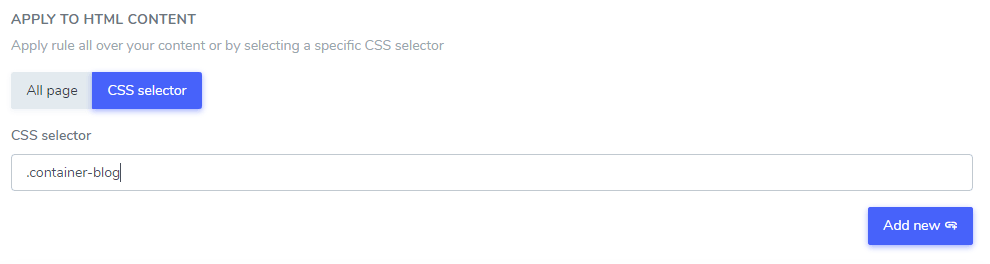
この例では、 「Netflix プレーヤー」、「PrimeVideo プレーヤー」、「YouTube プレーヤー」は、.blog CSS セレクタに含まれる HTML コンテンツ内でのみ翻訳から除外されます。
URLコンテンツ内のテキストを無視する
追加したテキストをURL自体から除外することができます。つまり、「PrimeVideo player」はURL内でそのまま残ります。例えば、「www.domain.com/prime-video-player」は翻訳されません。.

URLの変更: 稼働中のウェブサイトコンテンツのURLを変更する設定には注意してください。404エラーが発生する可能性があり、リダイレクトが必要になる場合があります。
タグを使用してコンテンツの翻訳を除外する
翻訳対象から除外するには、HTMLコンテンツの任意の場所にタグを追加できます: translate=”no”
HTML コンテナーの下にあるすべてのコンテンツは、すべてのサブ要素を含めて翻訳されません。.
タグによる HTML 除外の例:
<div translate=”no”>
<p>このテキストは全く翻訳されません</p>
</div>