
音声検索の東南アジアでのトレンドは、ユーザーがコンテンツと対話する方法を変えており、テクニカルSEOはローカル言語や文化的な行動に適応する必要があります。会話形式の質問ベースのクエリが増えるにつれて、企業はこれらのパターンに最適化することで目立たなければなりません。
文化的および多言語的なニュアンス(コードスイッチング、ローカルスラング、方言のバリエーションなど)は、検索の解釈方法に影響します。SEO戦略は、自然言語、ロングテールクエリ、スキーママークアップや多言語インデックスなどの適切なテクニカル設定に焦点を当てる必要があります。.
東南アジアにおける音声検索の採用トレンドと主要市場

東南アジアにおける音声検索の採用動向は、日常生活で音声技術への依存度が高まる消費者行動の変化を反映し、大きな成長を示しています。インドネシア、タイ、フィリピン、ベトナムなどの国々が、このトレンドを牽引する主要市場であり、インターネットの普及とテクノロジーに精通した若年層がこれを支えています。デジタルマーケットのデータによると、ユーザーはますますテキストから音声検索に切り替え、完全な文や会話的なフレーズに焦点を当てています。
によるとDemand Sageのデータでは、世界のインターネットユーザーの約20.5%が音声検索を利用しており、2025年までにアクティブな音声アシスタントの総数は84億ユニットに達するとのことです。東南アジアの特定のデータは利用できませんが、この世界的なトレンドは、この地域がこの成長に大きく貢献していることを示しています。
Google、Amazon、Microsoftなどの大手テクノロジー企業は、東南アジアへの投資を増やしており、市場の潜在力に自信を持っていることを示しています。たとえば、Googleは、マレーシアにデータセンターとクラウドサービスを構築するために20億ドルの投資を発表し、音声ベースの検索サービスをサポートします。
したがって、言語や方言の多様性などの課題があるにもかかわらず、東南アジアにおける音声検索の市場潜在力は非常に大きく、地元のニーズに応える戦略を立てる企業は、大きな競争優位性を持つことになります。.
音声クエリの形作る文化的および多言語のニュアンス
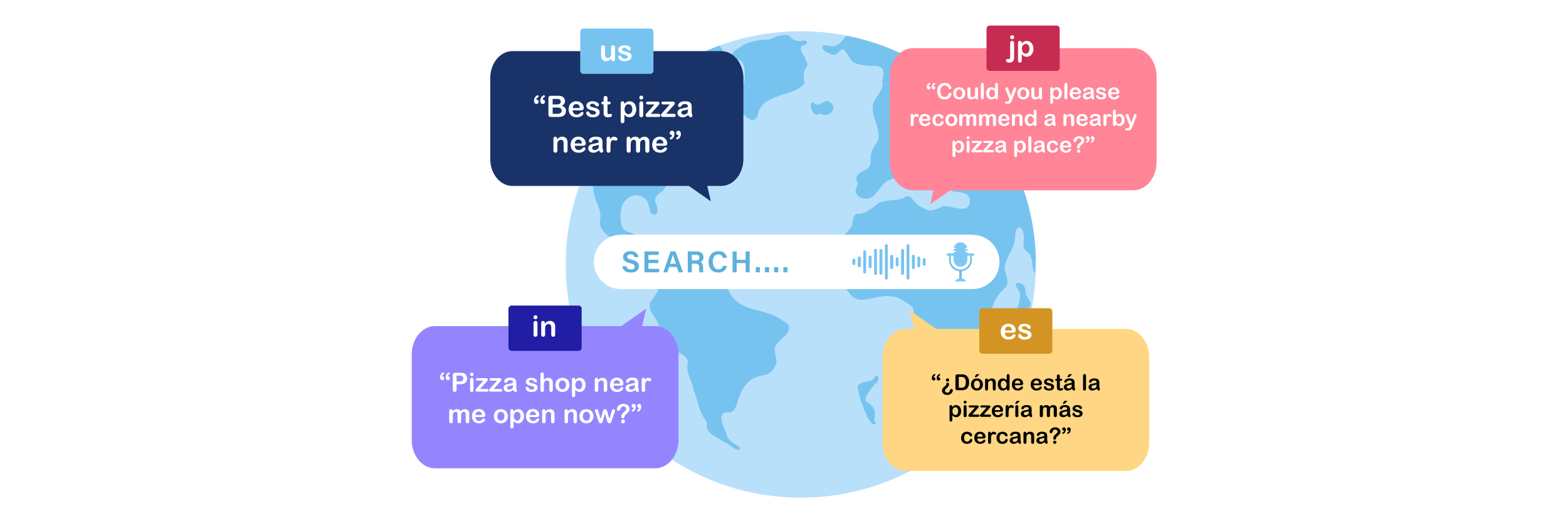
文化と言語の多様性は、東南アジアにおける音声検索の動作に深く影響しています。ユーザーは日常のコミュニケーションのパターンを反映する方法で、言語、方言、非公式の発話を組み合わせることが多く、検索エンジンがクエリを正確に解釈する上でユニークな課題が生じます。これらのニュアンスを理解することは、音声検索のためのコンテンツを最適化する上で極めて重要です。.
日常会話におけるコードスイッチング
東南アジアでは、人々が会話の中で言語を切り替えることが一般的で、例えば、ローカル言語と英語を組み合わせることがあります。このコードスイッチングは自然に会話の中で起こり、検索エンジンが音声クエリを解釈する方法に影響します。クエリには2つの言語のキーワードが含まれる可能性があるため、コンテンツが両方の言語に対応することが重要になります。.
SEO戦略では、主要なコンテンツ、見出し、メタデータに多言語フレーズを組み込む必要があります。一般的なコードスイッチングパターンを認識することで、どちらの言語のクエリでも関連する結果を取得でき、全体的な可視性とユーザーの満足度が向上します。.
方言、アクセント、非公式な言語パターン
地域の方言やアクセントは発音を大きく変え、音声認識システムでの誤解を招く可能性があります。短縮形や地域の表現を含む非公式な発話は、さらに複雑さを増します。検索エンジンは、これらのクエリを標準的なコンテンツに正しくマッチングするのに苦労する可能性があります。.
この問題に対処するために、コンテンツ作成者は、コンテンツやメタデータ内に代替の表記、音声のバリエーション、または口語表現を含めることができます。このアプローチは、さまざまな地域からの音声クエリが適切に理解され、マッチングされることを保証し、オーディエンス全体での検索精度を高めます。.
クエリで英語と地元のスラングを混ぜる

多くのユーザーは、地元のスラングと英語を混ぜて検索します。特に、技術、エンターテイメント、または製品関連のトピックで顕著です。たとえば、ユーザーは「Best gadget murah di Jakarta」と言って、英語とインドネシア語を組み合わせることがあります。これらのハイブリッド形式を無視すると、検索の機会を逃すことになります。.
音声検索のためのコンテンツ最適化では、一般的に使用されるスラングを特定し、それを標準的な言語用語とともに含める必要があります。これにより、検索エンジンは会話形式のクエリをより効果的にマッチさせ、ハイブリッド言語の検索結果に表示される可能性を高めます。.
短縮されたフレーズと完全な文のクエリ
キーボード入力による検索とは異なり、音声検索は単一のキーワードではなく、完全な文として表現されることが多い。ユーザーは「クアラルンプールで安いナシレマクはどこで見つかりますか?」と尋ねるかもしれないが、「安いナシレマク KL」と入力することはない。このように、より会話的な表現へのシフトは、コンテンツが直接的な回答を提供するためにどのように構造化されるべきかを変更する。.
これに対応するために、コンテンツは簡潔で自然な言語の回答を提供し、質問ベースの見出しやFAQセクションを含める必要がある。完全な文の形式で回答を構成することで、音声アシスタントが正確な結果をユーザーに抽出して提供する可能性が高まる。.
現地語での丁寧な表現と敬称の使用
タイ語やジャワ語などの東南アジアの言語では、ユーザーは音声検索に丁寧な表現や敬称を含めることがあります。これは、「フォーマル」なデバイスや公共の場で話すときに特に一般的です。これらの形式を無視すると、検索の正確性が低下する可能性があります。.
コンテンツ作成者は、関連する場合は、敬意のある用語や代替の形式を含めることを検討する必要があります。これにより、ユーザーの意図に一致し、丁寧な表現を含むクエリでも正確で関連性の高い結果が得られるようになります。.
検索意図における宗教的および文化的用語

ユーザーは、ローカルな風習、休日、または儀式を反映して、音声検索で宗教的または文化的用語を頻繁に使用します。クエリには、「ラマダンのレシピ」や「バリ島の寺院の営業時間」などのフレーズが含まれる場合がありますが、これらは標準的なSEOキーワードリサーチ
コンテンツに文化的に関連する用語や文脈を含めることで、これらのユーザーの意図に沿ったものになります。企業やコンテンツ制作者は、文化的な影響を受けたクエリを予測し、ローカルな文脈に合わせたコンテンツ内で直接的な回答を提供することで、表示の可視性を向上させることができます。.
ASRに影響を与える発音のバリエーション
自動音声認識(ASR)は、地域や年齢に関連する発音の違いにより、単語を誤って解釈する可能性があります。たとえば、ジャカルタで発音される単語は、スラバヤやペナンではわずかに異なる音に聞こえる可能性があり、音声クエリのマッチングでエラーが発生する可能性があります。.
これを軽減するために、コンテンツ制作者は一般的な発音のバリエーションを考慮し、音声つづりを入れたり、自然な音声を反映したFAQスタイルのコンテンツを使用したりすることができます。これにより、音声クエリが正しく理解され、関連するコンテンツに一致するようになり、多様なユーザーグループ間で検索の有効性が向上します。.
音声検索におけるテクニカルSEOの課題

音声検索は、クエリがより長く、会話的で、多言語であることが多いため、独自のテクニカルSEOの課題を引き起こします。コンテンツが発見可能であり、正しくインデックスされ、直接的な回答のために構造化されていることを確認するには、慎重な最適化が必要です。企業は、これらの進化する要求に対応するためにSEO戦略を適応させる必要があります。
ロングテールおよび会話型クエリの処理
音声クエリは通常、入力された検索よりも長く、自然な文の形をとることがよくあります。これにより、標準的なキーワードターゲティングでは、ユーザーが質問を表現する方法の多様性をカバーできないため、SEOの課題が生じます。短いキーワードのみをターゲットとするコンテンツは、音声検索からの貴重なトラフィックを見逃す可能性があります。.
以下のスクリーンショットは、「安いホテルバリ」のようなテキストベースの検索と、「バリで2泊用の安いホテルはどこにありますか?」のような完全な文の音声検索の違いを示しています。.
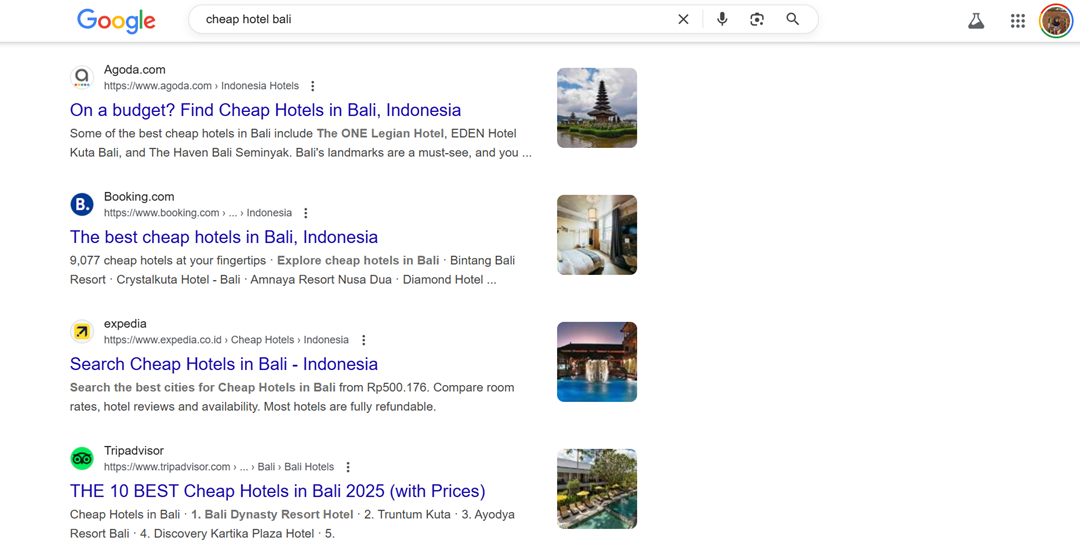
両者の意図は同じですが、言語構造は大きく異なります。コンテンツが短いキーワードにのみ最適化されている場合、このような会話型の検索結果を見逃す可能性があります。.
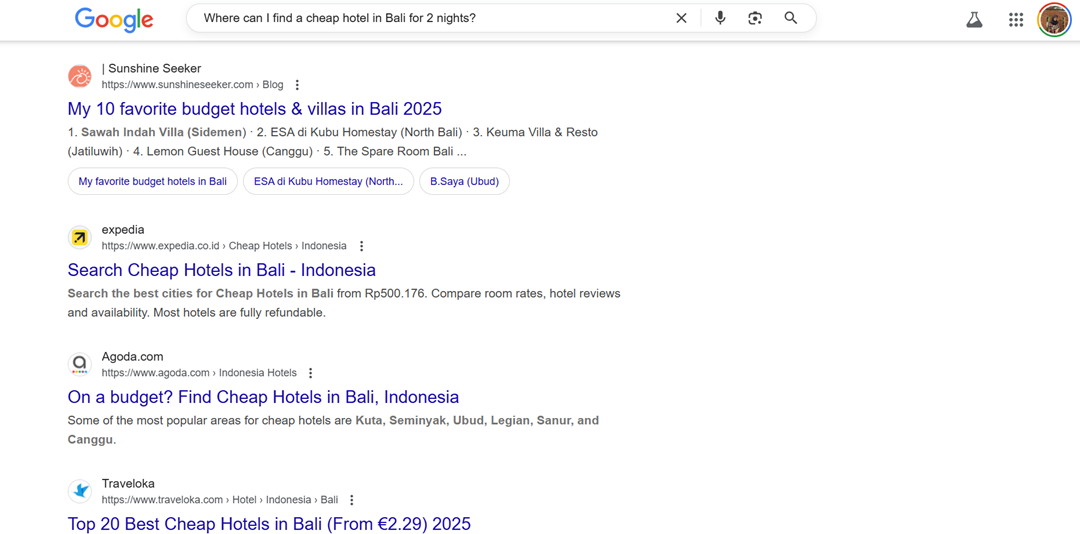
これに対処するために、ウェブサイトは完全な文のクエリを反映するロングテールキーワードを統合する必要があります。実際のユーザークエリを分析し、会話型の言語を含むようにコンテンツを更新することで、検索エンジンがクエリを関連ページに適切にマッチさせ、音声検索の可視性を向上させることができます。.
直接的な回答のためのコンテンツの構造化
音声アシスタントは、明確で簡潔な回答を提供するコンテンツを好みます。1つの課題は、情報を簡単に抽出して音声で読み上げることができるように構造化することです。音声検索プラットフォームは、密集した段落や不明瞭なフォーマットのページを見落とす可能性があります。.
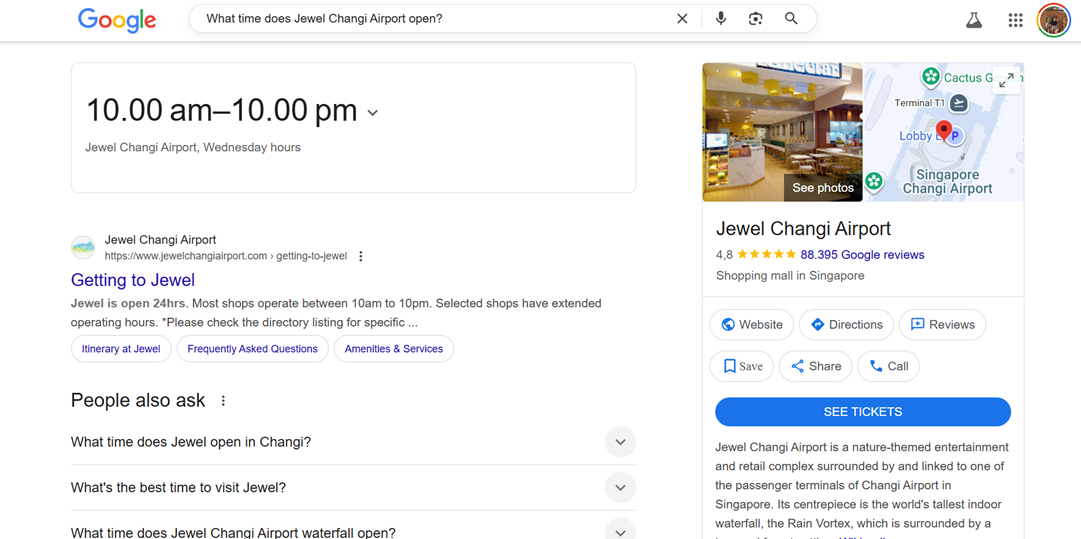
見出し、箇条書き、短い段落を使用すると、コンテンツが直接的な回答として際立ちます。FAQセクションやハイライトされた要約により、検索エンジンが最も関連性の高い情報を簡単に識別できるようになり、音声レスポンスで特集される可能性が向上します。たとえば、次のキーワード「ジュエルチャンギ空港は何時に開きますか?」をGoogleで検索すると、営業時間と関連するFAQのスニペットがすぐに表示されます。.
質問ベースの検索パターンに最適化する
多くの音声検索は、「タナロット寺院への行き方は?」のような質問として行われます。従来のSEOは、質問の意図ではなくキーワードに焦点を当てることが多く、可視性が制限されます。これにより、さまざまな可能なクエリを予測して最適化するという課題が生じます。.
これを克服するには、コンテンツを質問と回答の形式で作成する必要があります。一般的な質問を模倣した見出しを使用し、回答を自然に統合することで、音声クエリがコンテンツに正確に一致し、検索関連性が向上します。.
言語間でのクロール可能性とインデックス可能性の向上
適切なhreflangタグ、言語固有のサイトマップ、およびクリーンなURL構造は、検索エンジンが言語と地域ターゲティングを理解するのに役立ちます。これにより、インデックス可能性が向上し、ユーザーが優先言語で最も関連性の高い結果を取得できるようになります。.
ローカライズされたバージョン間で重複コンテンツを管理する

異なる言語または地域で同様のページが作成されると、重複コンテンツが発生する可能性があります。これは大きな課題です。検索エンジンは、どのバージョンをランク付けするかを決定するのに苦労し、音声検索の可視性を低下させる可能性があるためです。正規タグを使用することで、各ローカライズされたページが一意の関連コンテンツを提供し、この問題を軽減します。適切なコンテンツの差別化により、音声クエリが最も適切なページに向けられ、ユーザーエクスペリエンスと検索パフォーマンスが維持されます。
しかし、数十の言語バージョンにわたって手動で管理するのは時間の浪費になる可能性があります。
などの翻訳・ローカライズソリューションLinguiseは、SEOに適したURLを自動生成し、標準タグを適用し、各翻訳バージョンが重複コンテンツではなく一意のページとして扱われるようにします。これにより、企業は多言語音声検索の最適化をインデックス化の競合をリスクなく拡大できます。
音声駆動型SERPのスキーママークアップ範囲
音声検索は、関連する回答を迅速に特定するために構造化データに依存することがよくあります。課題は、スキーママークアップが、マルチリンガルコンテンツやローカライズされたバージョンを含むページ間で一貫して実装されていることを確認することです。
FAQ、HowTo、Productなどのスキーマタイプを使用すると、検索エンジンが音声応答の情報を簡単に抽出できます。定期的な監査と構造化データの更新は、正確性を維持し、音声駆動型検索結果の可視性を向上させるのに役立ちます。.
音声検索最適化のためのコンテンツ戦略

音声検索のためのコンテンツ最適化には、従来のSEO手法からの転換が必要です。音声検索クエリは会話的で、しばしば質問形式であるため、コンテンツは自然に質問に答え、容易に理解でき、実際のユーザー意図を反映するように構造化されなければなりません。戦略的なアプローチにより、コンテンツは音声クエリで発見可能で、高いランキングを獲得します。.
自然言語と質問ベースのキーワードを最適化する
音声検索クエリは、短いキーワードではなく、完全な文で表現されることが多いです。これにより、「フランスで最高のコーヒーを見つけるにはどこに行けばよいですか?」のような自然言語フレーズや質問ベースのキーワードをターゲットにすることが不可欠となり、「最高のコーヒーフランス」といった単純な表現ではなくなります。
見出しやFAQ、本文にこれらのフレーズを含めると、検索エンジンが会話形式のクエリと一致するのに役立ちます。たとえば、旅行ウェブサイトでは、「ウブドの人気アトラクションは何ですか?」という質問に答えるFAQページを作成し、音声検索トラフィックを直接ターゲットにすることができます。.
翻訳を超えたコンテンツのローカライズ

ユーザーは多くの場合、ネイティブ言語で検索し、文化的に関連のあるコンテンツを期待します。コンテンツを単に翻訳するだけでは十分ではありません。 ローカライズされたコンテンツ は、例、通貨、測定単位、およびコンテキストをローカルの慣習に適応させる必要があります。
たとえば、マレーシアをターゲットとするレシピサイトでは、マレーシアのユーザーになじみのあるローカルな食材名や測定単位を使用し、文字通りの翻訳ではなく、エンゲージメントを向上させ、音声検索が意味のある結果を返すようにする必要があります。.
音声に適したフォーマットを作成する
コンテンツは、音声アシスタントが読み上げやすいように構造化する必要があります。短い段落、箇条書き、番号付きの手順、明確な見出しは、音声アシスタントが情報を効率的に抽出するのに役立ちます。.
たとえば、「ガーデンズ・バイ・ザ・ベイの訪れ方」ガイドでは、ベイフロントMRTからの番号付きの行き方と重要なポイントを箇条書きで示すことで、ユーザーが簡潔な音声指示を受けられるようになり、音声検索の使い勝手を向上させます。.
権威を失わずに会話調を使う

音声検索ユーザーは、自然でわかりやすい口調を期待しています。ただし、コンテンツは、特に技術、健康、財務のトピックに関して、信頼性と権威を維持する必要があります。あまりにもカジュアルに書くと信頼性を損なう可能性があり、あまりにもフォーマルに書くとロボットのような印象を与える可能性があるため、会話調と情報提供のバランスを適切にとることが重要です。.
マリーナベイサンズのような場所への行き方を長い段落で説明するのではなく、短い順を追った手順に分けることで、人間の読者や音声アシスタントが処理しやすくなります。スクリーンショットベースのガイド、たとえば“MRTでマリーナベイサンズに行く方法”を箇条書きや番号付きリストで表示すると非常に効果的です。モバイルでスキャンしやすいだけでなく、GoogleアシスタントやSiriで読み上げたときにも、指示が明確で実行可能なままです。
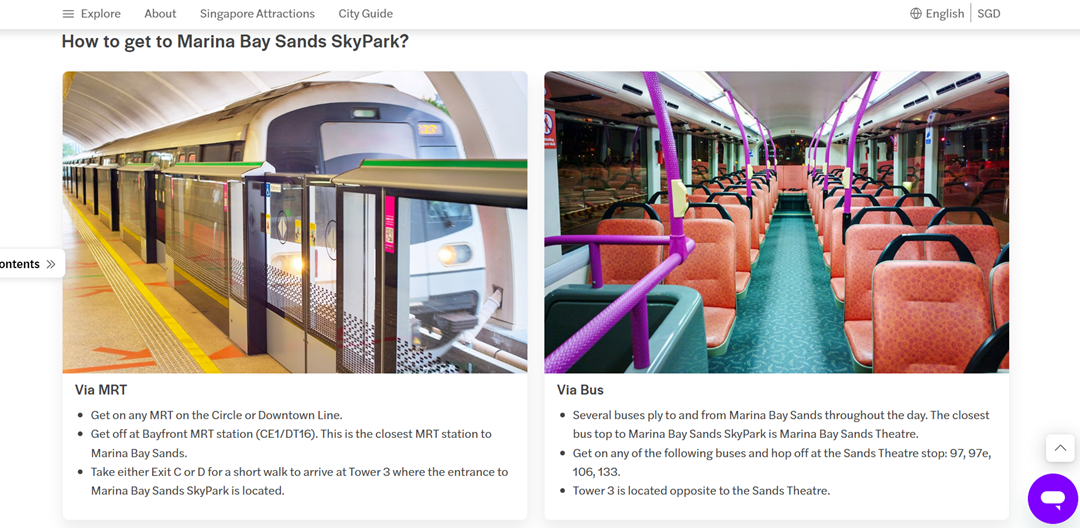
コンテンツを現実の検索シナリオに合わせる
即時のニーズや日常の状況が音声検索のクエリの駆動力となることがよくあります。一般的な検索コンテキストを理解することで、ユーザーの意図に直接応えるコンテンツを作成できます。.
たとえば、シンガポールのレストランウェブサイトには、「オーチャードロードの近くで午後9時以降に営業しているハラルレストランはどこですか?」という質問に答えるコンテンツを含めることができます。これにより、ユーザーは現実の状況に合った実用的な回答を得ることができ、音声検索のエンゲージメントが向上する可能性が高まります。.
結論
東南アジアの音声検索のトレンドは、人々が情報を検索する方法を変えています。短いキーワードを入力するのではなく、友人に話しかけるように直接質問するようになりました。音声で質問することがより自然で文化的文脈に合っているため、SEOはもはや硬いキーワードだけに焦点を当てることはできません。ブランドは、この地域のユーザーがどのように言語を混ぜ、ローカルスラングを使用し、さらには宗教的または丁寧な要素を質問に組み込むかを理解する必要があります。.
ボイス検索のためのテクニックルSEOは、競合力を維持すル新しい基礎です。ブランドが、コンバーサーショナルな質問に適応したコンテンツ構造を使用し、適切なスキーママークアップを使用し、深いロカライゼーションを実行すルことで、ボイス検索結果により簡単に表示されます。もし、手動で複数のバージョンを作成することなく、自動的にセオに優しいマルチリンガルコンテンツを最適化したいといア_NO_2が最も実用的なスタートアップションです。


