
Голосовой поиск тенденции в Юго-Восточной Азии меняют то, как пользователи взаимодействуют с контентом, требуя от технической SEO адаптироваться к местным лингвистическим и культурным особенностям. По мере роста разговорных, вопросно-ориентированных запросов, бизнесу необходимо оставаться видимым, оптимизируя под эти шаблоны.
Культурные и многоязычные нюансы, такие как переключение кода, местный сленг и диалектные вариации, влияют на то, как интерпретируются поисковые запросы. Стратегии SEO должны сосредоточиться на естественном языке, длинных запросах и правильной технической настройке, такой как разметка схемы и многоязычная индексация.</a>.
Тенденции внедрения и ключевые рынки голосового поиска в Юго-Восточной Азии

Тенденция внедрения голосового поиска в Юго-Восточной Азии демонстрирует значительный рост, отражая изменения в поведении потребителей, которые все больше полагаются на голосовые технологии в повседневной жизни. Страны, такие как Индонезия, Таиланд, Филиппины и Вьетнам, являются основными рынками, стимулирующими этот тренд, поддерживаемыми растущей интернет-пенетрацией и технически грамотной молодежью.Данные Digital Market показывают, что пользователи все чаще переключаются с текстового на голосовой поиск, фокусируясь на полных предложениях и разговорных фразах.
Согласно данным Demand Sage, примерно 20,5% глобальных интернет-пользователей используют голосовой поиск, при этом общее количество активных голосовых помощников достигнет 8,4 миллиарда единиц к 2025 году. Хотя конкретных данных по Юго-Восточной Азии нет, этот глобальный тренд указывает на то, что регион вносит значительный вклад в этот рост.
Крупные технологические компании, такие как Google, Amazon и Microsoft, увеличили свои инвестиции в Юго-Восточную Азию, что отражает их уверенность в потенциале рынка. Например, Google объявил об инвестициях в размере $2 млрд в строительство центров обработки данных и облачных сервисов в Малайзии, что будет поддерживать голосовые поисковые сервисы.
Таким образом, несмотря на такие проблемы, как разнообразие языков и диалектов, рыночный потенциал голосового поиска в Юго-Восточной Азии огромен, и компании, которые смогут адаптировать свои стратегии к местным потребностям, получат значительное конкурентное преимущество.
Культурные и многоязычные нюансы, формирующие голосовые запросы
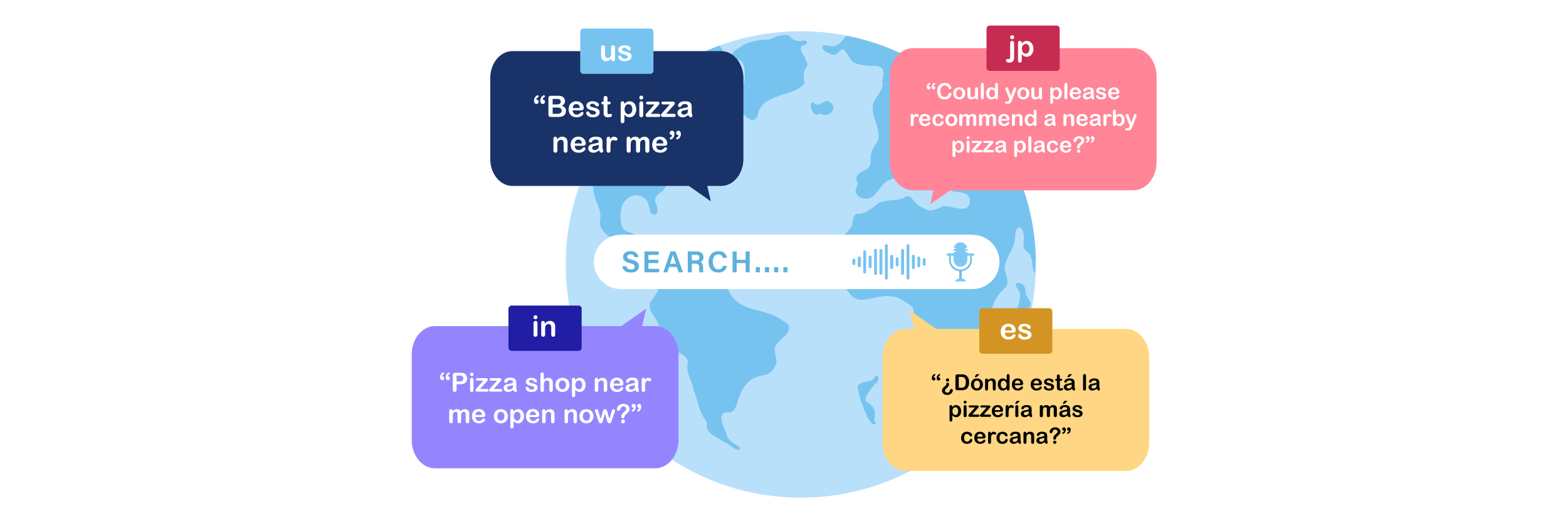
Культурное и лингвистическое разнообразие глубоко влияет на поведение голосового поиска в Юго-Восточной Азии. Пользователи часто сочетают языки, диалекты и неформальную речь таким образом, что отражает повседневные модели общения, создавая уникальные проблемы для поисковых систем в точной интерпретации запросов. Понимание этих нюансов имеет решающее значение для оптимизации контента для голосового поиска.
Переключение кода в повседневной речи
В Юго-Восточной Азии люди часто переключаются между языками в середине предложения, например, сочетая местный язык с английским. Это переключение кода происходит естественно в разговоре и влияет на то, как поисковые системы интерпретируют голосовые запросы. Запрос может содержать ключевые слова из двух языков, что делает важным для контента учитывать оба языка.
Стратегии SEO должны включать смешанные языковые фразы в ключевые содержания, заголовки и метаданные. Признание общих моделей переключения кода обеспечивает возможность запросов на любом языке получать релевантные результаты, улучшая общую видимость и удовлетворенность пользователей.
Диалекты, акценты и неформальные языковые шаблоны
Региональные диалекты и акценты могут существенно изменить произношение, что приводит к неправильному толкованию в системах распознавания голоса. Неформальная речь, включая сокращения или местные выражения, добавляет еще один слой сложности. Поисковые системы могут испытывать трудности с правильным сопоставлением этих запросов со стандартным содержанием.
Чтобы решить эту проблему, создатели контента могут включать альтернативные написания, фонетические вариации или разговорные термины в содержание и метаданные. Этот подход помогает обеспечить, чтобы голосовые запросы из разных регионов были правильно поняты и сопоставлены, повышая точность поиска среди аудитории.
Смешивание английского с местным сленгом в запросах

Многие пользователи смешивают английские слова с местным сленгом в своих поисковых запросах, особенно в темах, связанных с технологиями, развлечениями или продуктами. Например, пользователь может сказать: «Лучший гаджет murah ди Jakarta», объединив английский и индонезийский языки. Игнорирование этих гибридных форм может привести к упущенным возможностям в поиске.
Оптимизация контента для голосового поиска требует выявления часто используемого сленга и включения его наряду со стандартными языковыми терминами. Это позволяет поисковым системам более эффективно сопоставлять разговорные запросы, повышая вероятность появления в результатах поиска для гибридных языковых запросов.
Укороченные фразы vs. полносоставные запросы
В отличие от поисковых запросов, вводимых с клавиатуры, голосовые запросы часто представляют собой полные предложения, а не отдельные ключевые слова. Пользователи могут спросить: «Где можно найти недорогой наси lemak в Куала-Лумпуре?» вместо того, чтобы набрать «дешевый наси lemak KL». Этот сдвиг в сторону более разговорных формулировок меняет то, как должен быть структурирован контент, чтобы давать прямые ответы.
Чтобы адаптироваться, контент должен предлагать краткие ответы на естественном языке и включать заголовки или разделы FAQ, основанные на вопросах. Формулирование ответов в форме полных предложений увеличивает вероятность того, что голосовые помощники смогут извлечь и доставить точные результаты пользователям.
Использование вежливых форм и honorifics в местных языках
В некоторых языках Юго-Восточной Азии, таких как тайский или яванский, пользователи включают вежливые формы или почетные титулы в свои голосовые запросы. Это особенно распространено при общении с устройствами, воспринимаемыми как "формальные", или в общественных местах. Игнорирование этих форм может снизить точность поиска.
Создателям контента следует учитывать включение уважительных терминов или альтернативных форм, где это уместно. Это помогает сопоставить намерения пользователя, гарантируя, что запросы, содержащие вежливый язык, по-прежнему приводят к точным и актуальным результатам.
Религиозная и культурная терминология в намерениях поиска

Пользователи часто включают религиозные или культурные термины при выполнении голосовых поисков, отражая местные обычаи, праздники или ритуалы. Запросы могут включать фразы вроде "рецепт Рамадана" или "часы работы храма в Бали", которые могут не появиться в стандартномисследовании ключевых слов SEO.
Включение культурно релевантной терминологии и контекста в контент помогает соответствовать этим пользовательским намерениям. Бизнесы и создатели контента могут улучшить видимость, предвосхищая культурно обусловленные запросы и предоставляя прямые ответы в контенте, адаптированном к локальным контекстам.
Вариации произношения, влияющие на ASR
Автоматическое распознавание речи (ASR) может неправильно интерпретировать слова из-за региональных или возрастных различий в произношении. Например, слово, произнесенное в Джакарте, может звучать немного иначе в Сурабае или Пенанге, что потенциально может вызвать ошибки при совпадении голосовых запросов.
Чтобы смягчить это, создатели контента могут учитывать общие варианты произношения, включать фонетические написания или использовать контент в стиле FAQ, отражающий естественную речь. Это обеспечивает правильное понимание голосовых запросов и их соответствие релевантному контенту, улучшая эффективность поиска среди разнообразных групп пользователей.
Технические проблемы SEO в голосовом поиске

Голосовой поиск вводит уникальные технические SEO проблемы, поскольку запросы часто бывают более длинными, разговорными и многоязычными. Обеспечение доступности контента, его правильной индексации и структуры для прямых ответов требует тщательной оптимизации. Компаниям необходимо адаптировать свои стратегии SEO, чтобы соответствовать этим меняющимся требованиям.
Обработка длиннохвостых и разговорных запросов
Голосовые запросы обычно длиннее, чем вводимые поиски, и часто принимают форму естественных предложений. Это создает проблемы для SEO, поскольку стандартное таргетирование ключевых слов может не охватывать разнообразие способов, которыми пользователи формулируют свои вопросы. Контент, который ориентирован только на короткие ключевые слова, может упустить ценный трафик из голосовых поисков.
На скриншоте ниже показано различие между текстовыми поисковыми запросами, такими как «дешевый отель Бали» и голосовыми поисковыми запросами с полными предложениями, такими как «Где я могу найти дешевый отель на Бали на 2 ночи?».
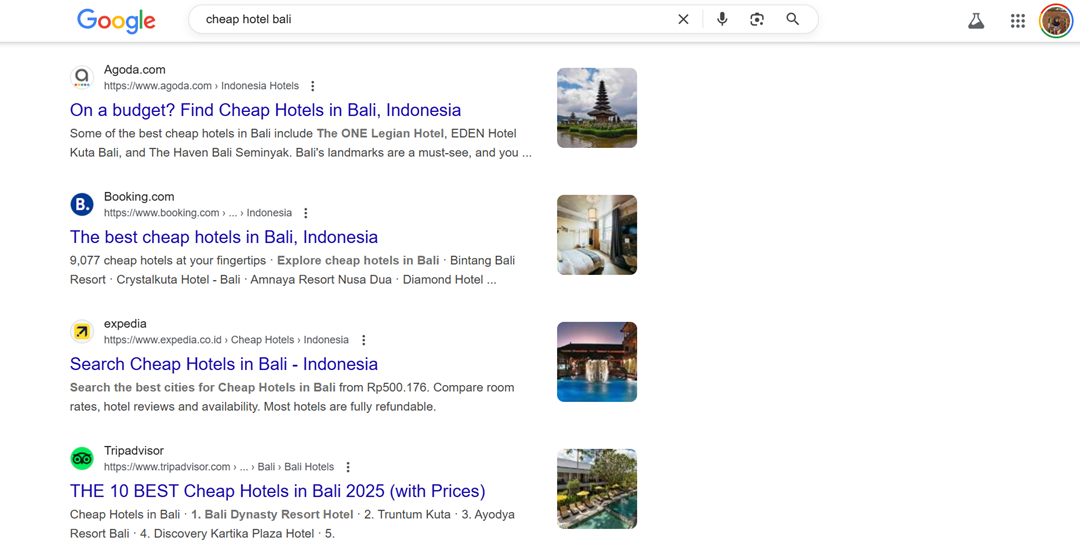
Хотя оба имеют одинаковый смысл, структура языка сильно различается, и если контент оптимизирован только для коротких ключевых слов, результаты разговорного поиска, подобные этому, могут быть пропущены.
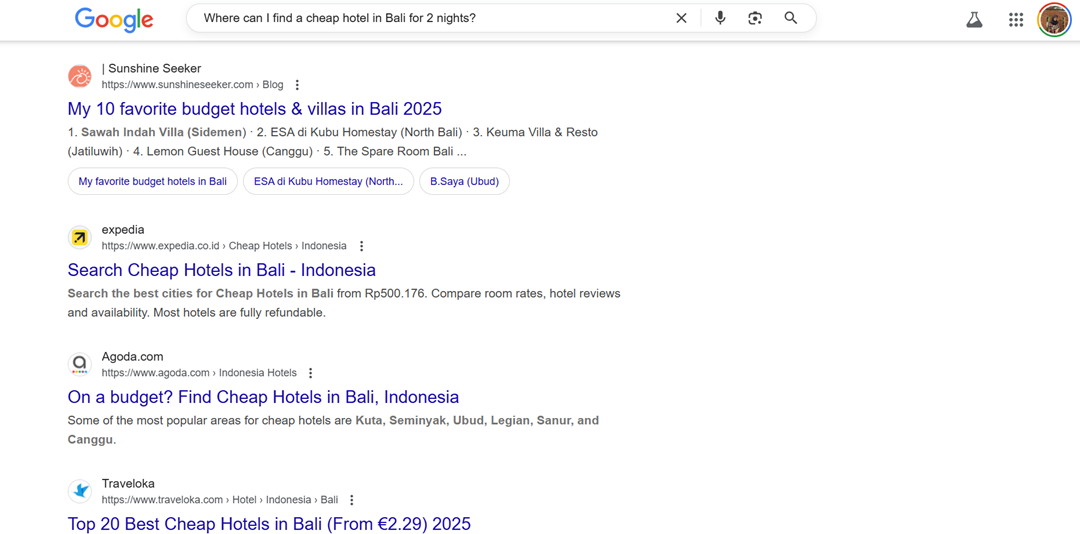
Чтобы решить эту проблему, веб-сайты должны интегрировать длинные ключевые слова, отражающие запросы целыми предложениями. Анализ реальных запросов пользователей и обновление контента для включения разговорного языка помогает поисковым системам лучше сопоставлять запросы с соответствующими страницами, улучшая видимость для голосового поиска.
Структурирование контента для прямых ответов
Голосовые помощники предпочитают контент, который дает четкие, краткие ответы. Одна из проблем заключается в структурировании информации так, чтобы она легко извлекалась и читалась вслух. Платформы голосового поиска могут пропустить страницы с плотными абзацами или нечетким форматированием.
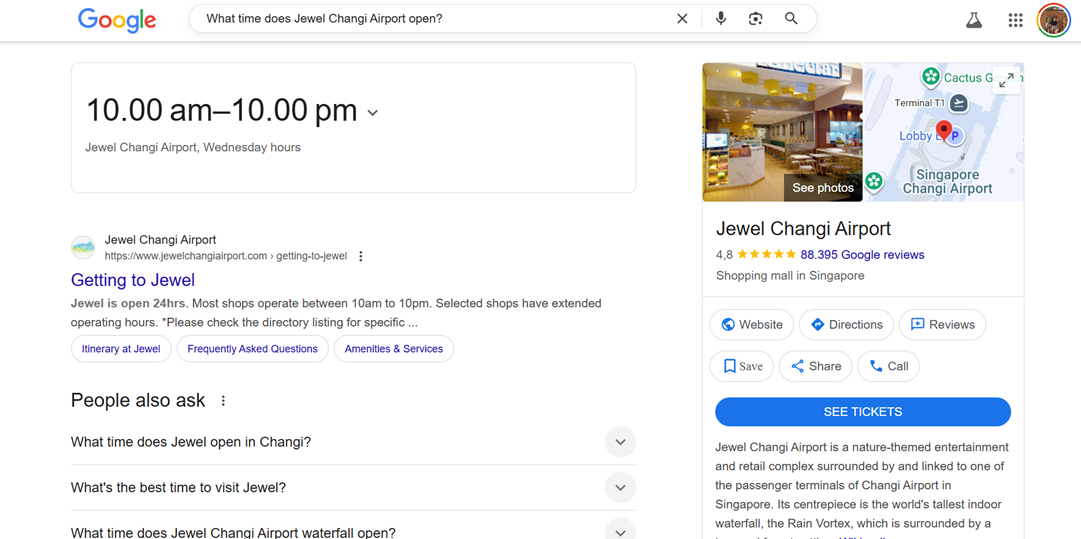
Использование заголовков, маркированных списков и коротких абзацев помогает контенту выделяться в качестве прямого ответа. Разделы FAQ и выделенные резюме облегчают поисковым системам идентификацию наиболее релевантной информации, повышая шансы быть представленным в голосовых ответах. Например, когда один из следующих ключевых слов, “В какое время открывается Jewel Changi Airport?” ищут в Google, фрагмент часов работы и соответствующие FAQ появляются сразу.
Оптимизация под шаблоны поиска на основе вопросов
Многие голосовые запросы формулируются в виде вопросов, таких как «Как добраться до храма Танах Лот?» Традиционный SEO часто фокусируется на ключевых словах, а не на намерении вопроса, ограничивая видимость. Это создает проблему прогнозирования и оптимизации различных возможных запросов.
Чтобы преодолеть это, контент должен быть создан в формате вопросов и ответов. Использование заголовков, имитирующих распространенные вопросы, и естественное включение ответов гарантирует, что голосовые запросы точно соответствуют контенту, повышая релевантность поиска.
Улучшение сканирования и индексации на разных языках
Многоязычный контент добавляет сложности к техническому SEO для голосового поиска. Обеспечение того, чтобы поисковые системы могли сканировать и индексировать страницы на нескольких языках, является сложной задачей, особенно когда сайты используют разные URL-адреса или поддомены для локализованного контента.
Правильные теги hreflang, языковые карты сайта и чистые структуры URL помогают поисковым системам понять язык и региональную направленность. Это улучшает индексируемость и гарантирует пользователям получение наиболее релевантных результатов на предпочитаемом языке.
Управление дублирующимся контентом в локализованных версиях

Дублирующийся контент может возникать при создании похожих страниц на разных языках или в разных регионах. Это является серьезной проблемой, поскольку поисковые системы могут испытывать трудности с определением версии для ранжирования, снижая видимость для голосовых поисков.Использование канонических тегов и обеспечение того, чтобы каждая локализованная страница предоставляла уникальный, релевантный контент, помогает смягчить эту проблему. Правильная дифференциация контента гарантирует, что голосовые запросы направляются на наиболее подходящую страницу, поддерживая пользовательский опыт и производительность поиска.
Однако ручное управление десятками языковых версий может быть трудоемким процессом.
Решение для перевода и локализации, такое как Linguise, автоматически генерирует SEO-дружественные URL-адреса, применяет канонические теги и гарантирует, что каждая переведенная версия рассматривается как уникальная страница, а не как дубликат контента, что позволяет бизнесу масштабировать оптимизацию мультиязыкового голосового поиска без риска конфликтов индексации.
Охват разметки схемы для голосовых SERP
Голосовой поиск часто полагается на структурированные данные для быстрого определения релевантных ответов. Одной из проблем является обеспечение разметки схемы последовательно на всех страницах, включая мультиязычный контент и локализованные версии.
Использование типов схемы, таких как FAQ, HowTo и Product, упрощает поисковым системам извлечение информации для голосовых ответов. Регулярный аудит и обновления структурированных данных помогают поддерживать точность и улучшать видимость в результатах голосового поиска.
Стратегия контента для оптимизации голосового поиска

Оптимизация контента для голосового поиска требует отхода от традиционных практик SEO. Поскольку голосовые запросы являются разговорными и часто основаны на вопросах, контент должен быть структурирован так, чтобы отвечать на вопросы естественно, быть легко воспринимаемым и отражать реальное намерение пользователя. Стратегический подход гарантирует, что контент будет обнаруживаемым и хорошо ранжироваться для голосовых запросов.
Оптимизация для естественного языка и ключевых слов на основе вопросов
Голосовые поисковые запросы часто формулируются в виде полных предложений, а не коротких ключевых слов. Это делает необходимым нацеливаться на фразы естественного языка и ключевые слова на основе вопросов, такие как «Где можно найти лучший кофе во Франции?» вместо простого «лучший кофе Франция»
Включение этих фраз в заголовки, списки часто задаваемых вопросов и основной текст помогает поисковым системам сопоставлять разговорные запросы. Например, сайт путешествий может создать страницу часто задаваемых вопросов с ответом на вопрос «Каковы главные достопримечательности в Убуде?» для прямой цели привлечения трафика голосового поиска.
Локализация контента за рамками перевода

Пользователи часто ищут на родном языке и ожидают культурно релевантного контента. Простое переведение контента недостаточно; локализация контента должна адаптировать примеры, валюту, единицы измерения и контекст к местным обычаям.
Например, кулинарный сайт, ориентированный на Малайзию, должен использовать местные названия ингредиентов и единицы измерения, знакомые малайзийским пользователям, а не буквальные переводы. Этот подход улучшает взаимодействие и гарантирует, что голосовой поиск возвращает значимые результаты.
Создание голосово-ориентированных форматов
Контент должен быть структурирован так, чтобы голосовые помощники могли легко читать вслух. Короткие абзацы, маркированные списки, пронумерованные шаги и четкие заголовки помогают голосовым помощникам эффективно извлекать информацию.
Например, руководство «Как посетить Сады у залива» с пронумерованными инструкциями от станции Bayfront MRT и ключевыми советами в маркированных списках позволяет пользователям получать краткие устные инструкции, повышая удобство использования голосового поиска.
Используйте разговорный тон, не теряя авторитетности

Пользователи голосового поиска ожидают естественного, понятного тона. Однако контент также должен сохранять достоверность и авторитетность, особенно для технических, медицинских или финансовых тем. Слишком неформальное написание может ослабить доверие, а слишком формальное может звучать роботизированно, поэтому ключом является достижение правильного баланса между разговорным и информативным.
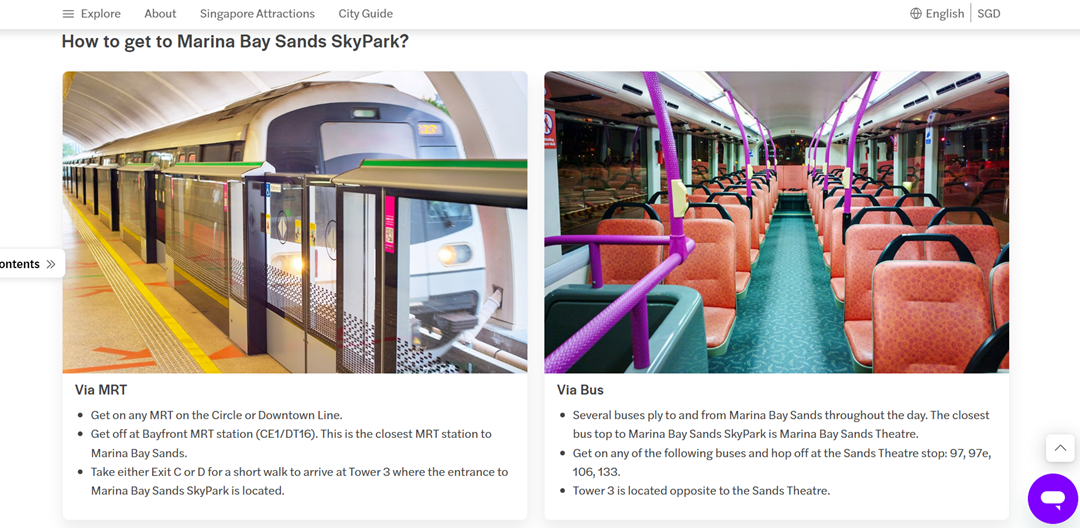
Вместо того, чтобы описывать направления к месту вроде Marina Bay Sands в длинных абзацах, разбивка инструкций на короткие последовательные шаги делает их гораздо проще для восприятия людьми и голосовыми помощниками. Руководства на основе скриншотов, такие как “Как добраться до Marina Bay Sands на MRT”, представленные в виде маркированных или нумерованных списков, работают исключительно хорошо. Они не только легко сканируются на мобильных устройствах, но и при чтении вслух Google Assistant или Siri инструкции остаются ясными и действенными.
Согласуйте контент с реальными сценариями поиска
Немедленные потребности или повседневные ситуации часто стимулируют голосовые запросы. Понимание общих контекстов поиска помогает создавать контент, напрямую отвечающий намерениям пользователя.
Например, веб-сайт ресторана в Сингапуре может включать контент, отвечающий на вопрос: “Какие халяльные рестораны открыты рядом с Орчард-Роуд после 21:00?” Это обеспечивает пользователей практическими ответами, соответствующими реальным ситуациям, повышая вероятность взаимодействия с голосовым поиском.
Заключение
Тенденции голосового поиска в Юго-Восточной Азии меняют то, как люди ищут информацию, больше не набирая короткие ключевые слова, а задавая вопросы напрямую, как будто разговаривая с другом. Поскольку задавать вопросы голосом более естественно и культурно контекстно, SEO больше не может сосредоточиться исключительно на жестких ключевых словах. Бренды должны понимать, как пользователи в этом регионе смешивают языки, используют местный сленг и даже включают религиозные или вежливые элементы в свои вопросы.
Техническая SEO для голосового поиска теперь является новой основой для сохранения конкурентоспособности. Компании, которые адаптируют структуру своего контента к разговорным вопросам, используют правильную разметку схемы и выполняют глубокую локализацию, будут появляться более легко в результатах голосового поиска. Если вы хотите оптимизировать многоязычный контент автоматически и SEO-дружественным способом без создания множества ручных версий, Linguise является наиболее практичным решением для начала работы.


