

Содержание
Добавить текст для игнорирования
Правило игнорирования текста позволит избежать перевода определенного текста при соблюдении заданных вами условий.
Обычно это первый тип правил, которые вы добавляете в систему перевода вашего сайта, чтобы исключить, например, название вашего продукта или компании. Чтобы добавить такое правило, подключитесь к своему сайту Панель управления Linguise > Нажмите «Правила» > «Добавить новое правило».
После этого вы сможете обновить подробные сведения о правиле игнорирования текста, в основном:
- Текст, который вы хотите исключить
- Условия исключения текста
- Название правила (видимое только вам на панели управления Linguise )
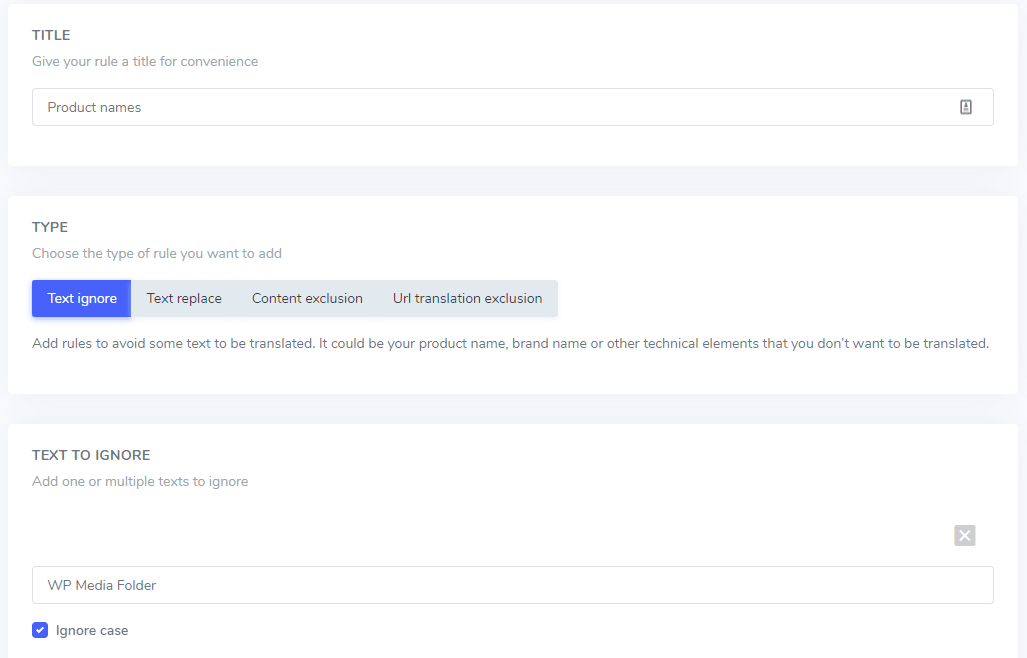
В поле «Текст для игнорирования» можно добавить несколько текстовых выражений, которые следует исключить в рамках одного правила. В нашем примере экран с несколькими названиями брендов, подлежащими исключению, будет выглядеть следующим образом:
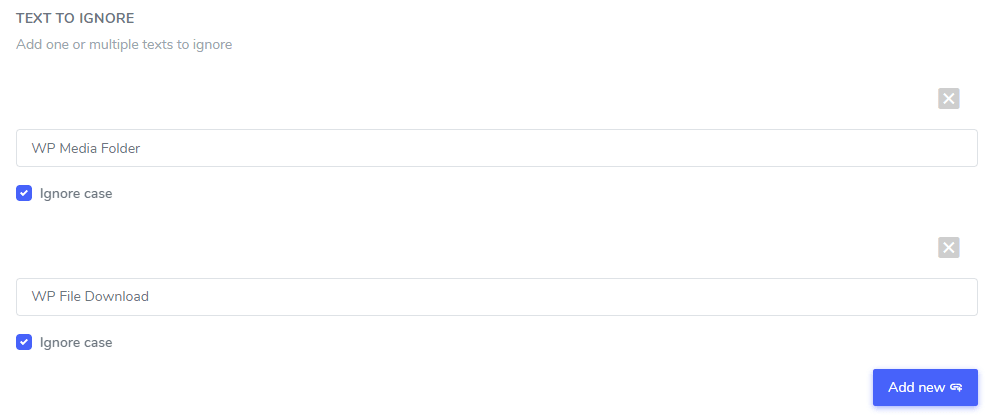
Игнорировать регистр: текстовый ввод чувствителен к регистру, это означает, что если флажок и строчные буквы как одинаковые. Пример исключения для перевода: «PrimeустановленVideoPlayer» и «PrimeVideoрегистрабудут исключены. , правило будет интерпретировать заглавные Player» с отключенной функцией учета
Игнорировать текст по URL-адресам
После того как вы настроите текст, который следует игнорировать при переводе, вы можете исключить его из всех URL-адресов вашего веб-сайта (используя опцию «ВСЕ URL») или из URL-адресов отдельных страниц.
- Исходный URL / Переведенный URL: Игнорировать текст перевода по определенному URL на исходном языке или по определенному URL на переведенном языке.
- символов подстановки / регулярных выражений: Игнорирование текста, переведенного для определенного URL-адреса, с помощью символов подстановки или регулярных выражений.
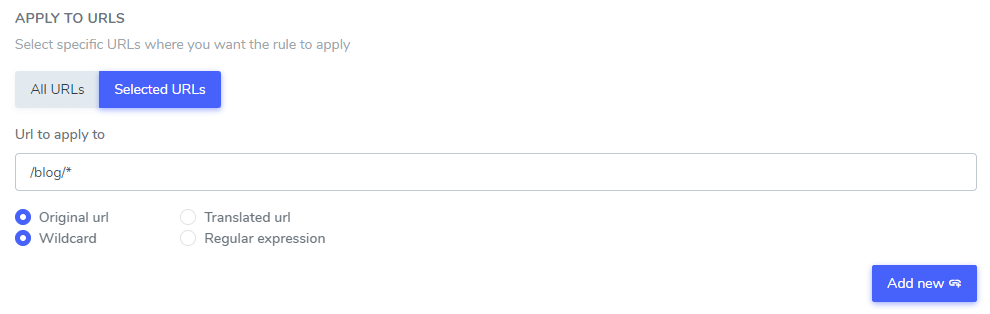
В этом примере: «Netflix player», «PrimeVideo player», «YouTube player» будут исключены из перевода во ВСЕХ URL-адресах веб-сайтов, начинающихся с www.domain.com/blog/
Для охвата, например, URL-адресов на нескольких языках, можно комбинировать несколько условий для URL-адресов.
Сопоставление шаблонов с помощью регулярных выражений
Использование регулярных выражений (RegEx) требует некоторого понимания синтаксиса и задействованных концепций .Регулярные выражения имеют разный синтаксис для URL-адресов и слов.
Хотя подстановочные символы проще понять и использовать для простых задач, регулярные выражения предоставляют более продвинутые и гибкие возможности сопоставления шаблонов.
Вот несколько распространённых примеров шаблонов сопоставления слов в регулярных выражениях:
- Сопоставьте любое слово, начинающееся с «Light»:
RegEx: Light\w
Пояснение: Сопоставляет любое слово, начинающееся с «Light», за которым следует ноль или более символов слова (\w). Это может соответствовать «Light», «Lightbulb», «Lightweight» и т. д. - Сопоставьте любое слово, оканчивающееся на «Light»:
RegEx: \w*Light
Пояснение: Сопоставляет любое слово, оканчивающееся на «Light», которому предшествует ноль или более символов. Это может соответствовать «Sunlight», «Daylight», «Spotlight» и т. д. - Сопоставление слова «Linguise» как целого слова:
RegEx: \bLinguise\b
Пояснение: Это совпадет с любой строкой, состоящей точно из символов слова «Linguiseне с другими словами, такими как LinguiseAppLinguise».
Более подробную информацию о регулярных выражениях можно найти здесь: https://www.regular-expressions.info/
Если у вас возникли вопросы, мы рекомендуем использовать подстановочные знаки (Wildcard) вместо регулярных выражений (Regular Expression) в обычных случаях.
Если у вас есть какие-либо вопросы, вы всегда можете связаться с нами, заполнив форму обратной связи!
Игнорировать текст по языку
Добавленный вами текст для игнорирования может быть исключен только для определенного языка или для всех языков. Это очень удобно, поскольку некоторые слова могут иметь одинаковое написание в разных языках, но требовать исключения только в одном из них. Например, слово «ilimitados» одинаково пишется на португальском и испанском языках.
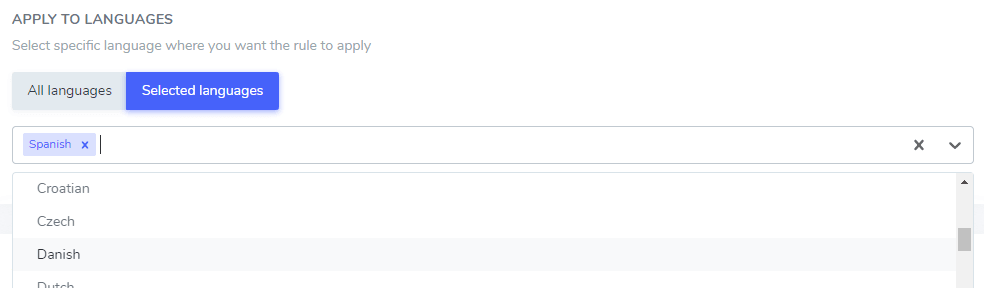
В этом примере слова «Netflix player», «PrimeVideo player», «YouTube player» будут исключены из перевода только на испанский язык.
Игнорировать текст в HTML-контенте
Добавленный вами текст ignore можно исключить из части HTML-контента с помощью одного или нескольких CSS-селекторов. Используя инспектор кода вашего браузера, вы можете найти любой CSS-селектор и добавить его следующим образом.
Получите CSS-селектор:

И добавьте это в настройки правила:
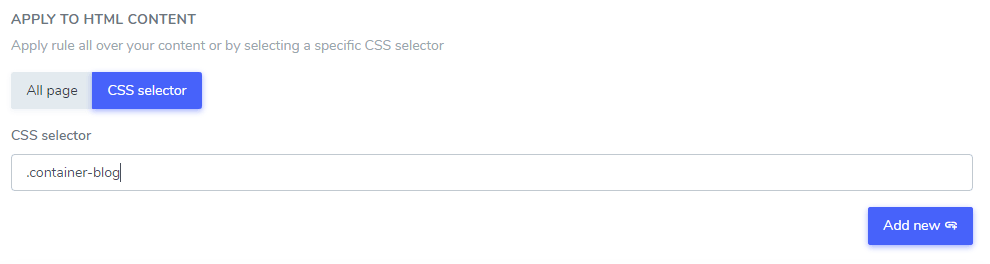
В этом примере: «Netflix player», «PrimeVideo player», «YouTube player» будут исключены из перевода только в HTML-контенте, указанном в CSS-селекторе .blog.
Игнорировать текст в содержимом URL-адресов
Добавленный вами текстовый параметр ignore можно исключить из самого URL-адреса, то есть "PrimeVideo player" останется в URL-адресе без изменений. Например: "www.domain.com/prime-video-player" не будет переведен.

Изменение URL-адресов: остерегайтесь конфигураций, изменяющих URL-адреса в работающем контенте веб-сайта. Это может привести к появлению URL-адресов с ошибкой 404, которые вам потребуется перенаправить.
Исключить перевод контента с помощью тега
Вы можете добавить тег в любом месте HTML-контента, чтобы исключить его из перевода: translate=”no”
Весь контент, находящийся внутри HTML-контейнера, НЕ будет переведен, включая все подэлементы.
Пример исключения HTML-кода по тегам:
<div translate=”no”>
<p>Этот текст вообще не будет переведён.</p>
</div>