

Inhaltsverzeichnis
Füge Text hinzu, der ignoriert werden soll
Die Textignorierregel verhindert, dass bestimmte Texte unter von Ihnen definierten Bedingungen übersetzt werden.
Dies ist üblicherweise die erste Regel, die Sie Ihrer Website-Übersetzung hinzufügen, um beispielsweise Ihren Produkt- oder Firmennamen auszuschließen. Um eine solche Regel hinzuzufügen, verbinden Sie sich mit Ihrem Linguise Dashboard > Klicken Sie auf Regeln > Neue Regel hinzufügen.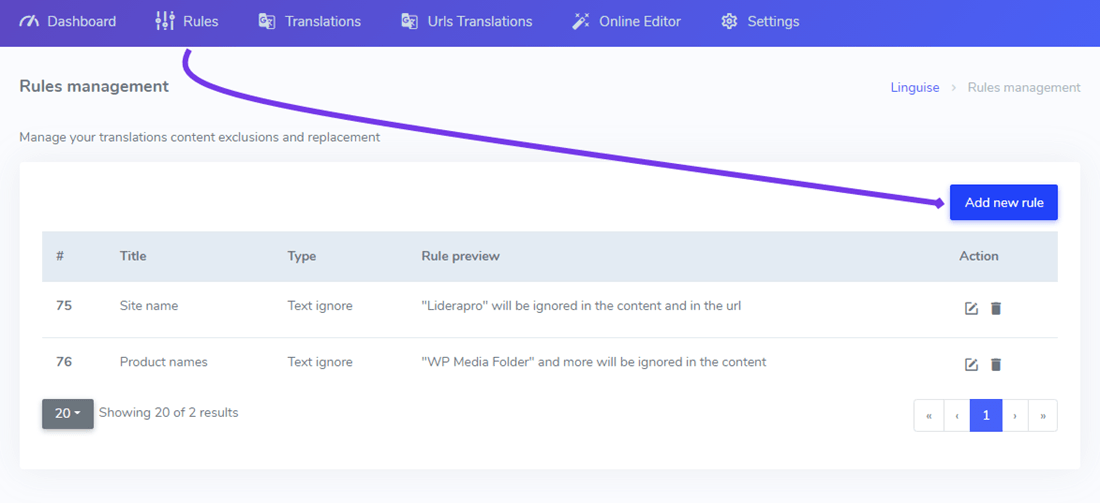
Anschließend können Sie die Details der Textignorierregel aktualisieren, insbesondere:
- Der Text, den Sie ausschließen möchten
- Die Bedingungen des Textausschlusses
- Der Regeltitel (nur für Sie im Linguise Dashboard sichtbar)
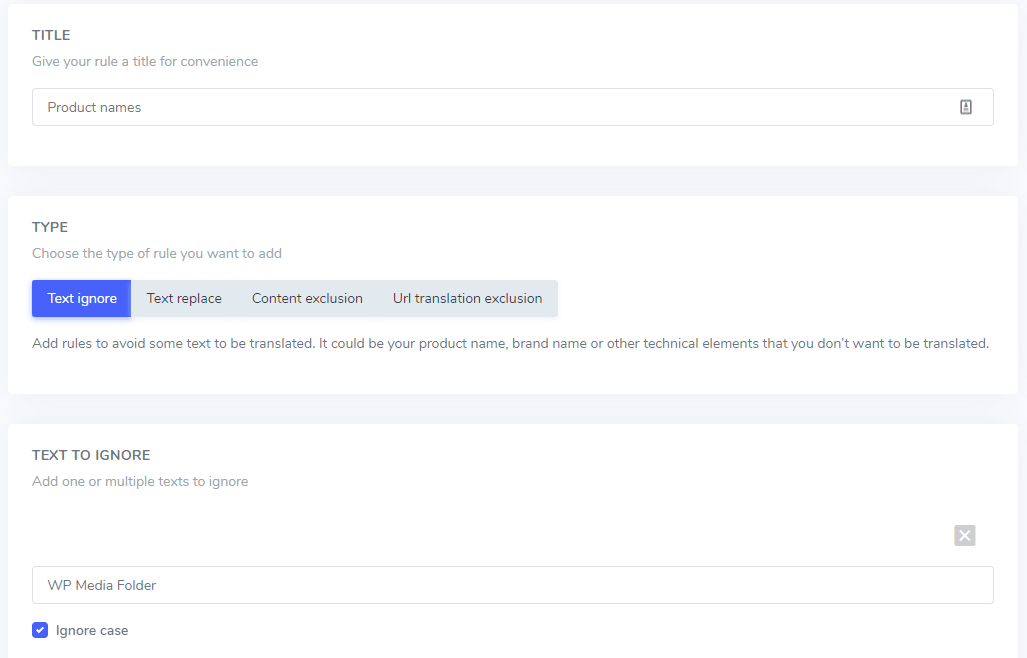
Im Feld „Zu ignorierender Text“ können Sie mehrere Textausdrücke hinzufügen, die gemäß derselben Regel ausgeschlossen werden sollen. In unserem Beispiel sieht der Bildschirm mit mehreren ausgeschlossenen Markennamen folgendermaßen aus:
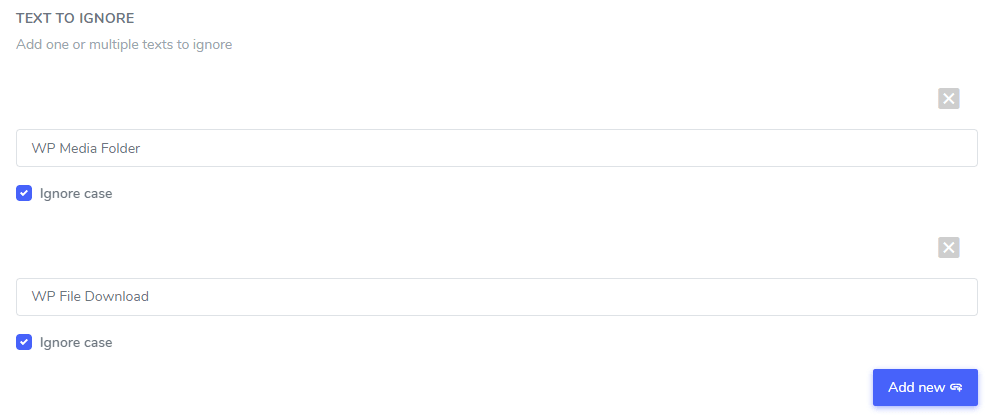
Groß-/Kleinschreibung ignorieren: Die Texteingabe unterscheidet zwischen Groß- und Kleinschreibung. Ist das Kontrollkästchen aktiviert, werden Groß- und Kleinbuchstaben als gleich interpretiert. Beispiel für einen Übersetzungsausschluss: „ Prime Video Player“ und „ Prime Video , / Kleinschreibung nicht berücksichtigt wird.
Text von URLs ignorieren
Sobald Sie die zu ignorierenden Texte festgelegt haben, können Sie diese entweder auf allen URLs Ihrer Website (mithilfe der Option ALLE URLs) oder auf bestimmten Seiten-URLs ausschließen.
- Original-URL / Übersetzte URL: Ignorieren Sie den Übersetzungstext einer bestimmten URL in der Originalsprache oder einer bestimmten URL in der übersetzten Sprache.
- Platzhalter / Regulärer Ausdruck: Ignorieren Sie den Übersetzungstext einer bestimmten URL mithilfe eines Platzhalters oder eines regulären Ausdrucks.
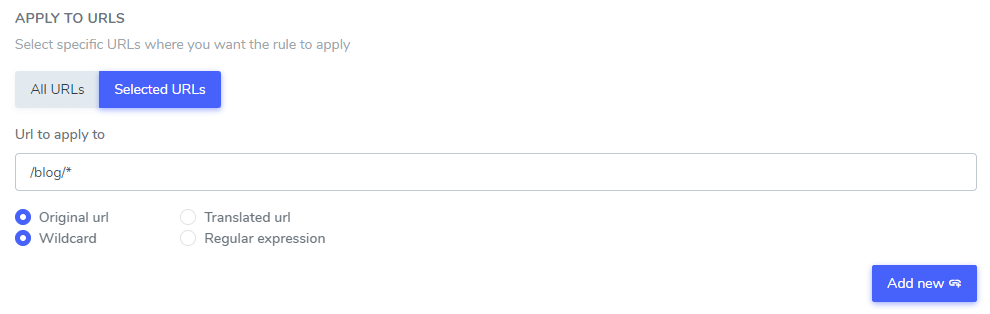
In diesem Beispiel werden „Netflix Player“, „PrimeVideo Player“ und „YouTube Player“ bei der Übersetzung ALLER Website-URLs, die mit www.domain.com/blog/ beginnen, ausgeschlossen.
Mehrere URL-Bedingungen können kombiniert werden, um beispielsweise URLs in mehreren übersetzten Sprachen abzudecken.
Mustervergleich mit regulären Ausdrücken
Die Verwendung regulärer Ausdrücke ( RegEx ) erfordert ein gewisses Verständnis der Syntax und der zugrunde liegenden . Reguläre Ausdrücke haben eine unterschiedliche Syntax für URLs und Wörter.
Während Wildcards leichter zu verstehen und für einfache Aufgaben zu verwenden sind, bietet RegEx fortgeschrittenere und flexiblere Möglichkeiten zur Mustererkennung.
Hier einige gängige Beispiele für Worterkennungsmuster regulärer Ausdrücke:
- Findet jedes Wort, das mit „Light“ beginnt:
RegEx: Light\w
Erklärung: Findet jedes Wort, das mit „Light“ beginnt und von null oder mehr Buchstaben (\w) gefolgt wird. Beispiele hierfür sind „Light“, „Lightbulb“, „Lightweight“ usw. - Findet jedes Wort, das mit „Light“ endet:
RegEx: \w*Light
Erklärung: Findet jedes Wort, das mit „Light“ endet und dem null oder mehr Buchstaben vorangestellt sind. Beispiele hierfür sind „Sunlight“, „Daylight“, „Spotlight“ usw. - Linguise “ als ganzes Wort
finden RegEx: \b Linguise \b
Erklärung: Dies findet jede Zeichenkette, die exakt aus den Zeichen des Wortes „ Linguise “ besteht. Dadurch wird sichergestellt, dass keine anderen Wörter wie Linguise App“ gefunden werden, sondern nur „ Linguise “.
Weitere Details zu regulären Ausdrücken finden Sie hier: https://www.regular-expressions.info/
Falls Sie diesbezüglich unsicher sind, empfehlen wir für den regulären Gebrauch
von Wildcards Bei Fragen können Sie uns jederzeit über unser Kontaktformular erreichen!
Text nach Sprache ignorieren
Der von Ihnen hinzugefügte Textausschluss kann entweder nur in bestimmten Sprachen oder in allen Sprachen gelten. Dies ist sehr praktisch, da manche Wörter in verschiedenen Sprachen gleich geschrieben werden, aber nur in einer Sprache ausgeschlossen werden müssen. Beispielsweise ist das Wort „ilimitados“ im Portugiesischen und Spanischen identisch.
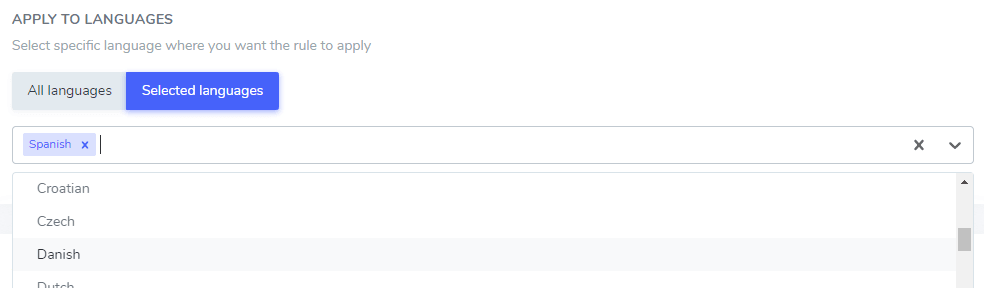
In diesem Beispiel werden „Netflix Player“, „PrimeVideo Player“ und „YouTube Player“ nur bei der Übersetzung ins Spanische ausgeschlossen.
Text im HTML-Inhalt ignorieren
Der von Ihnen hinzugefügte Text kann mithilfe eines oder mehrerer CSS-Selektoren aus einem Teil Ihres HTML-Inhalts ausgeschlossen werden. Mit dem Code-Inspektor Ihres Browsers können Sie beliebige CSS-Selektoren ermitteln und wie folgt hinzufügen.
Einen CSS-Selektor abrufen:

Und fügen Sie es in der Regelkonfiguration hinzu:
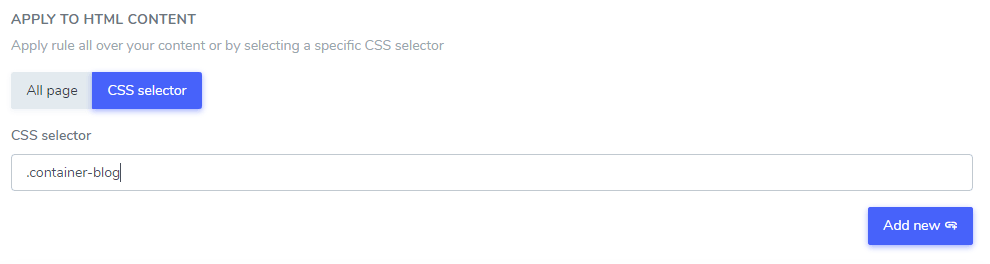
In diesem Beispiel werden „Netflix Player“, „PrimeVideo Player“ und „YouTube Player“ nur im HTML-Inhalt, der sich im CSS-Selektor .blog befindet, von der Übersetzung ausgeschlossen.
Text im Inhalt von URLs ignorieren
Der von Ihnen hinzugefügte Text, der ignoriert werden soll, kann aus der URL selbst ausgeschlossen werden. Das bedeutet, dass „PrimeVideo Player“ in URLs unverändert bleibt. Beispiel: „www.domain.com/prime-video-player“ wird nicht übersetzt.

URL-Änderung: Vorsicht vor Konfigurationen, die URLs auf Live-Websites verändern. Dies kann zu 404-Fehlern führen, die Sie umleiten müssen.
Inhaltsübersetzung mithilfe eines Tags ausschließen
Sie können an beliebiger Stelle in Ihrem HTML-Inhalt ein Tag einfügen, um Elemente von der Übersetzung auszuschließen: translate="no"
Der gesamte Inhalt innerhalb des HTML-Containers, einschließlich aller Unterelemente, wird NICHT übersetzt.
Beispiel für den HTML-Ausschluss durch ein Tag:
<div translate=”no”>
<p>Dieser Text wird überhaupt nicht übersetzt.</p>
</div>