
in spraakgestuurd zoeken in Zuidoost-Azië veranderen de manier waarop gebruikers met content omgaan, waardoor technische SEO zich moet aanpassen aan lokaal taalgebruik en culturele gewoonten. Naarmate meer vraaggestuurde zoekopdrachten ontstaan, moeten bedrijven zichtbaar blijven door te optimaliseren voor deze patronen.
Culturele en meertalige nuances, zoals code-switching, lokaal jargon en dialectvariaties, beïnvloeden hoe zoekopdrachten worden geïnterpreteerd. SEO-strategieën moeten zich richten op natuurlijke taal, long-tail zoektermen en de juiste technische instellingen, zoals schema-markup en meertalige indexering.
Adoptie trends en belangrijkste markten voor spraakzoeken in Zuidoost-Azië

De trend van spraakzoekadoptie in Zuidoost-Azië vertoont aanzienlijke groei, als gevolg van veranderingen in consumentengedrag die steeds meer afhankelijk zijn van spraaktechnologie in het dagelijks leven. Landen zoals Indonesië, Thailand, de Filipijnen en Vietnam zijn de belangrijkste markten die deze trend aansturen, ondersteund door toenemende internetpenetratie en een technisch onderlegde jonge bevolking. Digital Market data toont aan dat gebruikers steeds meer overschakelen van tekst naar spraakzoeken, met focus op complete zinnen en conversatie-uitdrukkingen.
Volgens Demand Sage-gegevens gebruiken ongeveer 20,5% van de wereldwijde internetgebruikers spraakzoekopdrachten, waarbij het totale aantal actieve spraakassistenten tegen 2025 8,4 miljard eenheden bereikt. Hoewel er geen specifieke gegevens beschikbaar zijn voor Zuidoost-Azië, wijst deze wereldwijde trend erop dat de regio aanzienlijk bijdraagt aan deze groei.
Grote technologiebedrijven zoals Google, Amazon en Microsoft hebben hun investeringen in Zuidoost-Azië verhoogd, wat hun vertrouwen in de markt weerspiegelt. Google heeft bijvoorbeeld een investering van $2 miljard aangekondigd om datacenters en cloud-diensten in Maleisië te bouwen, die spraakzoekdiensten zullen ondersteunen.
Dus, ondanks uitdagingen zoals taal- en dialectdiversiteit, is het marktpotentieel voor spraakzoeken in Zuidoost-Azië enorm, en bedrijven die hun strategieën kunnen aanpassen om aan lokale behoeften te voldoen, zullen een significant competitief voordeel hebben.
Culturele en meertalige nuances die spraakquery's vormgeven
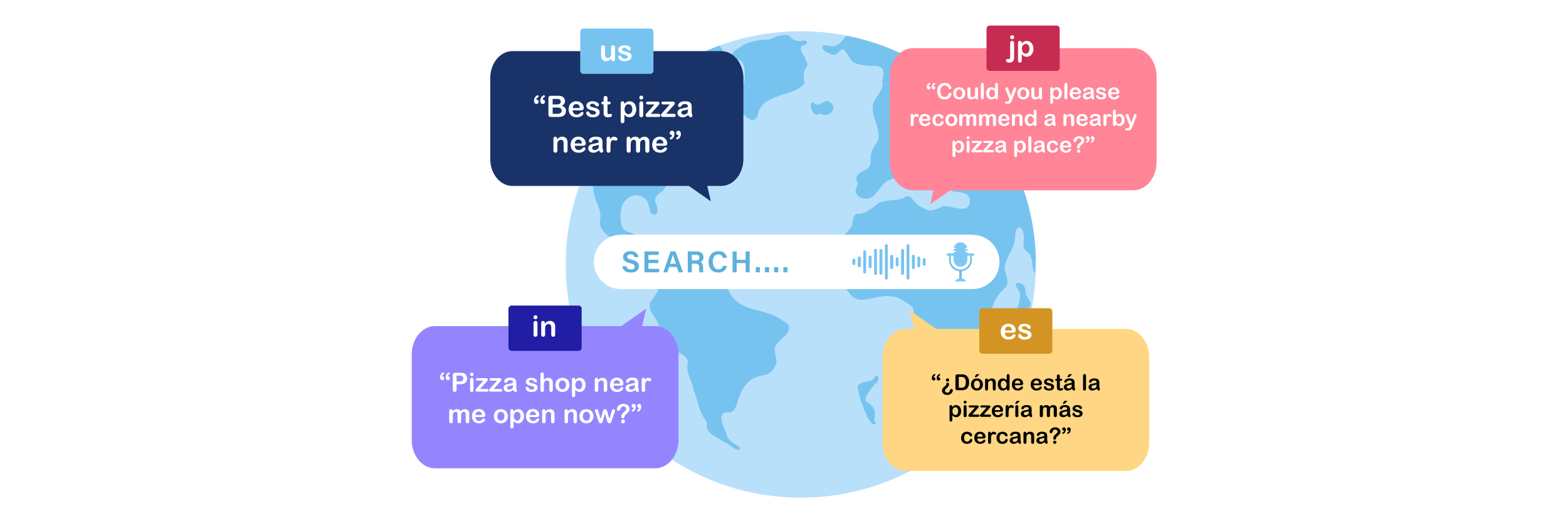
Culturele en linguïstische diversiteit heeft een grote invloed op het zoekgedrag via spraak in Zuidoost-Azië. Gebruikers combineren vaak talen, dialecten en informele spreektaal op een manier die de dagelijkse communicatiepatronen weerspiegelt. Dit zorgt voor unieke uitdagingen voor zoekmachines bij het correct interpreteren van zoekopdrachten. Het begrijpen van deze nuances is cruciaal voor het optimaliseren van content voor spraakgestuurd zoeken.
Code-switching in alledaagse spraak
In Zuidoost-Azië is het gebruikelijk dat mensen midden in een zin van taal wisselen, bijvoorbeeld door de lokale taal met Engels te combineren. Deze taalwisseling komt op natuurlijke wijze voor in gesprekken en beïnvloedt hoe zoekmachines spraakopdrachten interpreteren. Een zoekopdracht kan trefwoorden uit twee talen bevatten, waardoor het belangrijk is dat de inhoud beide talen aanspreekt.
SEO-strategieën moeten gemengdtalige frases opnemen in belangrijke inhoud, koppen en metadata. Het herkennen van de algemene code-switching-patronen zorgt ervoor dat zoekopdrachten in beide talen relevante resultaten opleveren, waardoor de algehele zichtbaarheid en gebruikerstevredenheid verbeteren.
Dialecten, accenten en informele taalpatronen
Regionale dialecten en accenten kunnen de uitspraak aanzienlijk wijzigen, wat leidt tot misinterpretatie in spraakherkenningssystemen. Informeel spraakgebruik, inclusief samentrekkingen of lokale uitdrukkingen, voegt een extra laag complexiteit toe. Zoekmachines kunnen moeite hebben om deze zoekopdrachten correct te matchen met standaardinhoud.
Om dit aan te pakken, kunnen contentmakers alternatieve spellingswijzen, fonetische variaties of omgangstermen opnemen in hun content en metadata. Deze aanpak helpt ervoor te zorgen dat stemquery's uit diverse regio's correct worden begrepen en gekoppeld, waardoor de zoeknauwkeurigheid over verschillende doelgroepen heen wordt verbeterd.
Het mengen van Engels met lokale slang in vragen

Veel gebruikers combineren Engelse woorden met lokale straattaal in hun zoekopdrachten, vooral in tech-, entertainment- of productgerelateerde onderwerpen. Een gebruiker kan bijvoorbeeld zeggen: "Best gadget murah di Jakarta," waarbij Engels en Indonesisch worden gecombineerd. Het negeren van deze hybride vormen kan leiden tot gemiste zoekkansen.
Het optimaliseren van content voor stemzoekopdrachten vereist het identificeren van veelgebruikte straattaal en het opnemen daarvan naast standaardtaaltermen. Dit stelt zoekmachines in staat om conversatiequery's effectiever te matchen, waardoor de kans groter wordt dat ze verschijnen in resultaten voor zoekopdrachten in hybride talen.
Verkorte zinnen versus volledige zinnen
In tegenstelling tot getypte zoekopdrachten komen stemquery's vaak als volledige zinnen in plaats van enkele trefwoorden. Gebruikers kunnen vragen: "Waar kan ik goedkoop nasi lemak vinden in Kuala Lumpur?" in plaats van "goedkoop nasi lemak KL" te typen. Deze verschuiving naar meer conversatie-uitdrukkingen verandert hoe inhoud moet worden gestructureerd om directe antwoorden te bieden.
Om de content aan te passen, moet deze beknopte antwoorden in natuurlijke taal bieden en vraaggerichte kopjes of FAQ-secties bevatten. Door antwoorden in volledige zinnen te formuleren, vergroot u de kans dat spraakassistenten accurate resultaten kunnen extraheren en aan gebruikers kunnen leveren.
Gebruik van beleefdheidsvormen en eretitels in lokale talen
In sommige Zuidoost-Aziatische talen, zoals Thai of Javaans, gebruiken gebruikers beleefde vormen of ere-titels in hun stemquery's. Dit is vooral gebruikelijk bij het spreken tot apparaten die worden gezien als "formeel" of in openbare omgevingen. Het negeren van deze vormen kan de zoeknauwkeurigheid verminderen.
Contentmakers zouden moeten overwegen om waar relevant respectvolle termen of alternatieve formuleringen te gebruiken. Dit helpt om de intentie van de gebruiker beter te begrijpen en ervoor te zorgen dat zoekopdrachten met beleefde taal nog steeds tot accurate en relevante resultaten leiden.
Religieuze en culturele terminologie in zoekintentie

Gebruikers nemen vaak religieuze of culturele termen op bij het doen van spraakzoekopdrachten, die lokale gebruiken, feestdagen of rituelen weerspiegelen. Zoekopdrachten kunnen zinnen bevatten zoals “Ramadan-recept” of “Openingsuren Bali-tempel,” die mogelijk niet voorkomen in standaard SEO-trefwoordonderzoek.
Het opnemen van cultureel relevante terminologie en context in content helpt om deze gebruikersintenties af te stemmen. Bedrijven en contentmakers kunnen de zichtbaarheid verbeteren door cultureel beïnvloede zoekopdrachten te voorzien en directe antwoorden te bieden binnen content die is afgestemd op lokale contexten.
Variaties in uitspraak die ASR beïnvloeden
Automatische spraakherkenning (ASR) kan woorden verkeerd interpreteren vanwege regionale of leeftijdsgebonden uitspraakverschillen. Een woord dat bijvoorbeeld in Jakarta wordt uitgesproken, kan enigszins anders klinken in Surabaya of Penang, wat mogelijk fouten veroorzaakt bij het matchen van spraakzoekopdrachten.
Om dit te mitigeren, kunnen contentmakers rekening houden met veelvoorkomende uitspraakvarianten, fonetische spellingswijzen toevoegen of FAQ-stijl content gebruiken die natuurlijke spraak weerspiegelt. Dit zorgt ervoor dat spraakaanvragen correct worden begrepen en gekoppeld aan relevante content, waardoor de zoekeffectiviteit over diverse gebruikersgroepen verbetert.
Technische SEO-uitdagingen in spraakzoekopdrachten

Spraakzoekopdrachten introduceren unieke technische SEO-uitdagingen omdat zoekopdrachten vaak langer, conversatie-achtig en meertalig zijn. Het waarborgen dat content vindbaar is, correct geïndexeerd en gestructureerd voor directe antwoorden vereist zorgvuldige optimalisatie. Bedrijven moeten hun SEO-strategieën aanpassen om aan deze evoluerende eisen te voldoen.
Het afhandelen van long-tail en conversationele zoekopdrachten
Spraakgestuurde zoekopdrachten zijn doorgaans langer dan getypte zoekopdrachten en nemen vaak de vorm aan van natuurlijke zinnen. Dit zorgt voor uitdagingen voor SEO, omdat standaard zoekwoordtargeting mogelijk niet alle manieren dekt waarop gebruikers hun vragen formuleren. Content die zich alleen richt op korte zoekwoorden kan waardevol verkeer van spraakgestuurde zoekopdrachten mislopen.
De onderstaande schermafbeelding toont het verschil tussen op tekst gebaseerde zoekopdrachten, zoals “goedkoop hotel bali” en spraakzoekopdrachten met volledige zinnen zoals “Waar kan ik een goedkoop hotel in Bali vinden voor 2 nachten?”.
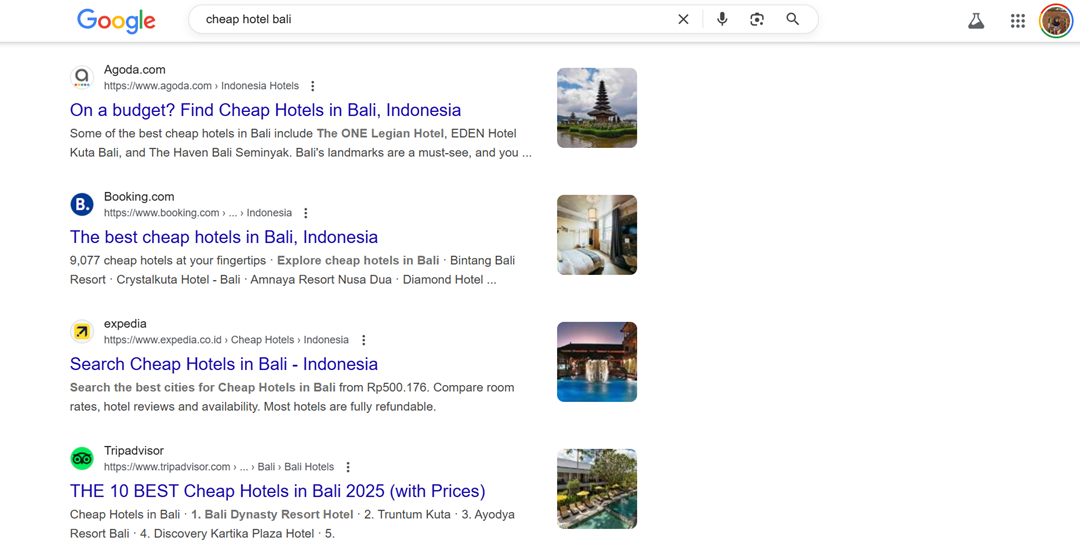
Hoewel beide hetzelfde doel hebben, is de taalstructuur heel anders, en als content alleen geoptimaliseerd is voor korte zoekwoorden, kunnen dit soort conversatiegerichte zoekresultaten gemist worden.
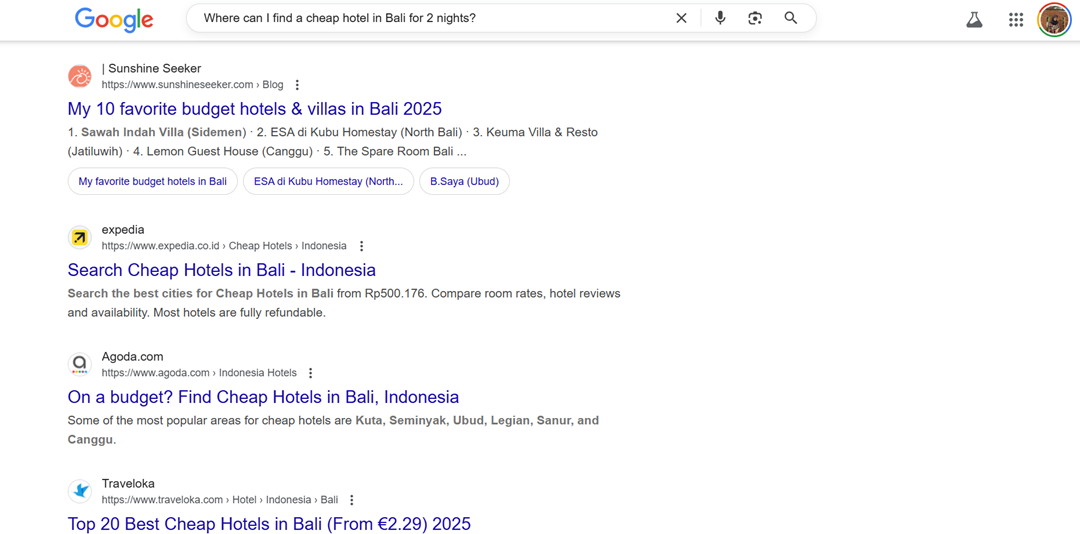
Om dit aan te pakken, zouden websites longtail-zoekwoorden moeten integreren die volledige zinnen weerspiegelen. Door daadwerkelijke zoekopdrachten van gebruikers te analyseren en de content aan te passen met spreektaal, kunnen zoekmachines zoekopdrachten beter koppelen aan relevante pagina's, waardoor de zichtbaarheid voor spraakgestuurd zoeken verbetert.
Het structureren van de inhoud voor directe antwoorden
Spraakassistenten geven de voorkeur aan inhoud die heldere, beknopte antwoorden biedt. Een uitdaging is het structureren van informatie zodat deze gemakkelijk kan worden geëxtraheerd en hardop kan worden voorgelezen. Spraakzoekplatforms kunnen pagina's met dichte alinea's of onduidelijke opmaak over het hoofd zien.
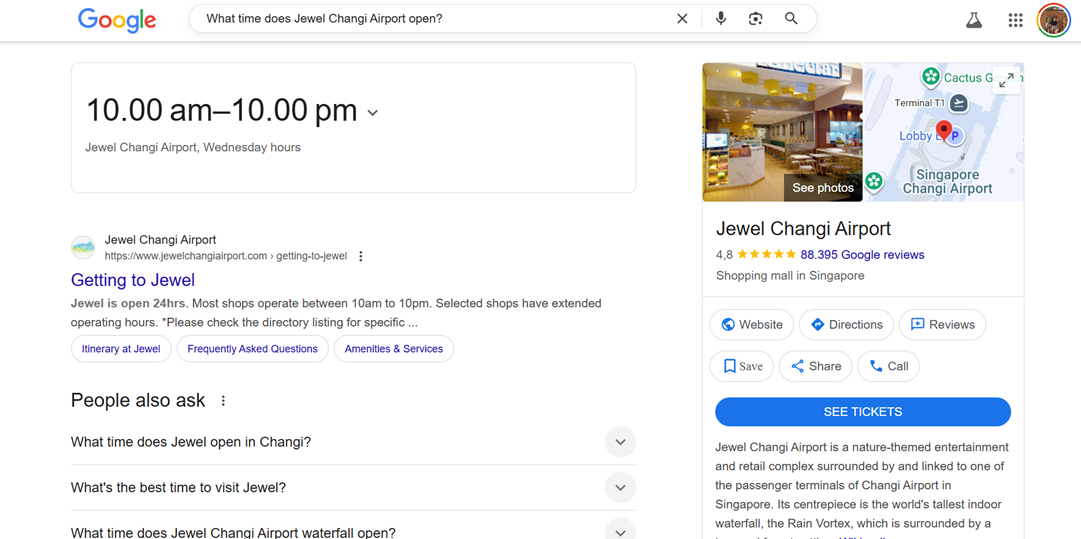
Het gebruik van kopjes, opsommingstekens en korte alinea's zorgt ervoor dat de inhoud opvalt als een direct antwoord. FAQ-secties en gemarkeerde samenvattingen maken het voor zoekmachines gemakkelijker om de meest relevante informatie te vinden, waardoor de kans groter wordt dat deze in spraakgestuurde antwoorden wordt weergegeven. Als er bijvoorbeeld op Google wordt gezocht naar een van de volgende zoekwoorden: "Hoe laat opent Jewel Changi Airport?", verschijnt er direct een overzicht van de openingstijden en relevante veelgestelde vragen.
Optimaliseren voor op vragen gebaseerde zoekpatronen
Veel spraakzoekopdrachten zijn opgesteld als vragen zoals “Hoe kom ik bij de Tanah Lot tempel?” Traditionele SEO richt zich vaak op sleutelwoorden in plaats van vraagintentie, waardoor de zichtbaarheid wordt beperkt. Dit zorgt voor de uitdaging om te voorspellen en te optimaliseren voor verschillende mogelijke zoekopdrachten.
Om dit te overwinnen, moet de inhoud worden opgesteld in vraag- en antwoordformaten. Het gebruik van koppen die veelgestelde vragen nabootsen en het natuurlijk integreren van antwoorden zorgt ervoor dat spraakzoekopdrachten nauwkeurig worden gekoppeld aan de inhoud, waardoor de zoekrelevantie wordt verbeterd.
Verbetering van crawlbaarheid en indexeerbaarheid in verschillende talen
Meertalige content voegt complexiteit toe aan technische SEO voor spraakzoekopdrachten. Het garanderen dat zoekmachines pagina's in meerdere talen kunnen crawlen en indexeren is uitdagend, vooral wanneer sites verschillende URL's of subdomeinen gebruiken voor gelokaliseerde content.
Juiste hreflang-tags, taalspecifieke sitemaps en schone URL-structuren helpen zoekmachines de taal en regionale targeting te begrijpen. Dit verbetert de indexeerbaarheid en zorgt ervoor dat gebruikers de meest relevante resultaten krijgen in hun voorkeurstaal.
Het beheren van dubbele content in gelokaliseerde versies

Dubbele inhoud kan voorkomen wanneer vergelijkbare pagina's worden gemaakt in verschillende talen of regio's. Dit is een grote uitdaging omdat zoekmachines moeite kunnen hebben om te bepalen welke versie moet worden gerangschikt, waardoor de zichtbaarheid voor spraakzoekopdrachten wordt verminderd. Canonical tags gebruiken en ervoor zorgen dat elke gelokaliseerde pagina unieke, relevante inhoud biedt, helpt dit probleem te verzachten. Een goede differentiatie van inhoud zorgt ervoor dat spraakquery's naar de meest geschikte pagina worden geleid, waardoor de gebruikerservaring en zoekprestaties behouden blijven.
Het handmatig beheren hiervan over tientallen taalversies kan echter veel tijd kosten.
Een vertaal- en lokalisatieoplossing zoals Linguise genereert automatisch SEO-vriendelijke URL's, past canonical tags toe en zorgt ervoor dat elke vertaalde versie wordt behandeld als een unieke pagina in plaats van dubbele inhoud, waardoor bedrijven de optimalisatie van meertalige spraakzoekopdrachten kunnen opschalen zonder indexatieconflicten te riskeren.
Schema-markupdekking voor spraakgestuurde SERP's
Stemzoekopdrachten zijn vaak afhankelijk van gestructureerde data om relevante antwoorden snel te identificeren. Een uitdaging is ervoor zorgen dat schema-opmaak consequent wordt geïmplementeerd op alle pagina's, inclusief meertalige content en gelokaliseerde versies.
Het gebruik van schema-types, zoals FAQ, HowTo en Product, maakt het voor zoekmachines gemakkelijker om informatie te extraheren voor stemreacties. Regelmatige audits en updates van gestructureerde data helpen de nauwkeurigheid te behouden en de zichtbaarheid in door stem aangestuurde zoekresultaten te verbeteren.
Contentstrategie voor optimalisatie van stemzoekopdrachten

Het optimaliseren van content voor spraakgestuurd zoeken vereist een andere aanpak dan traditionele SEO-methoden. Omdat spraakgestuurde zoekopdrachten conversatiegericht zijn en vaak vraagstelling bevatten, moet de content zo gestructureerd zijn dat vragen op een natuurlijke manier worden beantwoord, de inhoud gemakkelijk te begrijpen is en de werkelijke intentie van de gebruiker weerspiegelt. Een strategische aanpak zorgt ervoor dat de content vindbaar is en goed scoort in zoekresultaten voor spraakgestuurde zoekopdrachten.
Optimaliseer voor natuurlijke taal en op vragen gebaseerde sleutelwoorden
Stemzoekopdrachten worden vaak in volledige zinnen geformuleerd in plaats van korte sleutelwoorden. Dit maakt het essentieel om natuurlijke taalfragmenten en op vragen gebaseerde sleutelwoorden te targeten, zoals “Waar kan ik de beste koffie in Frankrijk vinden?” in plaats van simpelweg “beste koffie Frankrijk.”
Het opnemen van deze zinnen in koppen, FAQs en hoofdtekst helpt zoekmachines om conversatiequery's te matchen. Een reiswebsite kan bijvoorbeeld een FAQ-pagina maken die antwoord geeft op 'Wat zijn de topattracties in Ubud?' om voice search verkeer rechtstreeks te targeten.
Localiseer inhoud verder dan vertaling

Gebruikers zoeken vaak in hun moedertaal en verwachten cultureel relevante content. Het simpelweg vertalen van content is niet voldoende; bij lokalisatie moeten voorbeelden, valuta, meeteenheden en context worden aangepast aan de lokale gebruiken.
Een receptensite die gericht is op Maleisië, moet bijvoorbeeld lokale ingrediëntennamen en -maten gebruiken die vertrouwd zijn bij Maleisische gebruikers in plaats van letterlijke vertalingen. Deze aanpak verbetert de betrokkenheid en zorgt ervoor dat voice search zinvolle resultaten oplevert.
Maak voice-vriendelijke formaten
Inhoud moet zo gestructureerd zijn dat voice-assistenten deze gemakkelijk hardop kunnen lezen. Korte alinea's, opsommingen, genummerde stappen en duidelijke koppen helpen voice-assistenten om informatie efficiënt te extraheren.
Een gids zoals “Hoe bezoek je Gardens by the Bay” met genummerde instructies vanaf Bayfront MRT en belangrijke tips in opsommingstekens is bijvoorbeeld ideaal om gebruikers concise gesproken instructies te geven, waardoor de gebruiksvriendelijkheid voor spraakzoekopdrachten wordt verbeterd.
Gebruik een conversational toon zonder autoriteit te verliezen

Gebruikers van spraakzoekopdrachten verwachten een natuurlijke, gemakkelijk te begrijpen toon. De content moet echter ook geloofwaardigheid en autoriteit behouden, vooral voor technische, gezondheids- of financiële onderwerpen. Te casual schrijven kan het vertrouwen ondermijnen, terwijl te formeel schrijven robotachtig kan klinken, dus de sleutel is het vinden van de juiste balans tussen conversational en informatief.
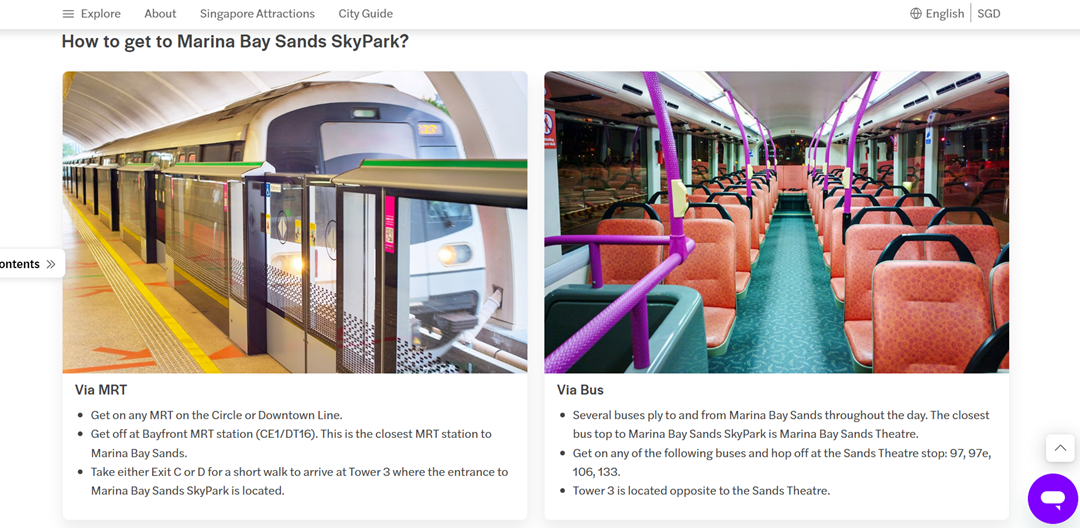
In plaats van richtingen naar een plek zoals Marina Bay Sands te beschrijven in lange alinea's, maakt het opsplitsen van de instructies in korte, opeenvolgende stappen het veel gemakkelijker voor menselijke lezers en spraakassistenten om te verwerken. Screenshot-gebaseerde handleidingen zoals “Hoe naar Marina Bay Sands te gaan via MRT” gepresenteerd in opsommingstekens of genummerde lijsten werken uitzonderlijk goed. Niet alleen zijn ze scannbaar op mobiel, maar wanneer ze hardop worden voorgelezen door Google Assistant of Siri, blijven de instructies duidelijk en uitvoerbaar.
Stem inhoud af op realistische zoekscenario's
Directe behoeften of alledaagse situaties sturen vaak voice queries aan. Het begrijpen van algemene zoekcontexten helpt bij het creëren van inhoud die rechtstreeks inspeelt op de intentie van de gebruiker.
Een restaurantwebsite in Singapore kan bijvoorbeeld inhoud bevatten die de vraag beantwoordt: “Welke halal-restaurants zijn open bij Orchard Road na 21.00 uur?” Dit zorgt ervoor dat gebruikers praktische antwoorden krijgen die passen bij realistische situaties, waardoor de kans op spraakzoekacties toeneemt.
Conclusie
Trends in zoekopdrachten via stem in Zuidoost-Azië veranderen hoe mensen naar informatie zoeken, niet langer korte trefwoorden typen, maar rechtstreeks vragen stellen alsof ze met een vriend praten. Omdat het stellen van vragen via stem natuurlijker en cultureel contextueel is, kan SEO niet langer uitsluitend focussen op starre trefwoorden. Merken moeten begrijpen hoe gebruikers in deze regio talen mengen, lokale slang gebruiken en zelfs religieuze of beleefde elementen in hun vragen opnemen.
Technische SEO voor spraakzoekopdrachten is nu de nieuwe basis voor het competitief blijven. Bedrijven die hun inhoudsstructuur aanpassen aan conversatievragen, het juiste schema-opmaak gebruiken en diepe lokalisatie uitvoeren, zullen gemakkelijker verschijnen in spraakzoekresultaten. Als u multitalige inhoud automatisch en SEO-vriendelijk wilt optimaliseren zonder veel handmatige versies te maken, Linguise is de meest praktische oplossing om aan de slag te gaan.


