

Inhoudsopgave
Voeg tekst toe die genegeerd moet worden
De regel 'tekst negeren' zorgt ervoor dat bepaalde tekst onder bepaalde door u te definiëren voorwaarden niet wordt vertaald.
Dit is meestal het eerste type regel dat u toevoegt aan de vertaling van uw website, bijvoorbeeld om uw product- of bedrijfsnaam uit te sluiten. Om zo'n regel toe te voegen, maakt u verbinding met uw Linguise dashboard > Klik op Regels > Nieuwe regel toevoegen.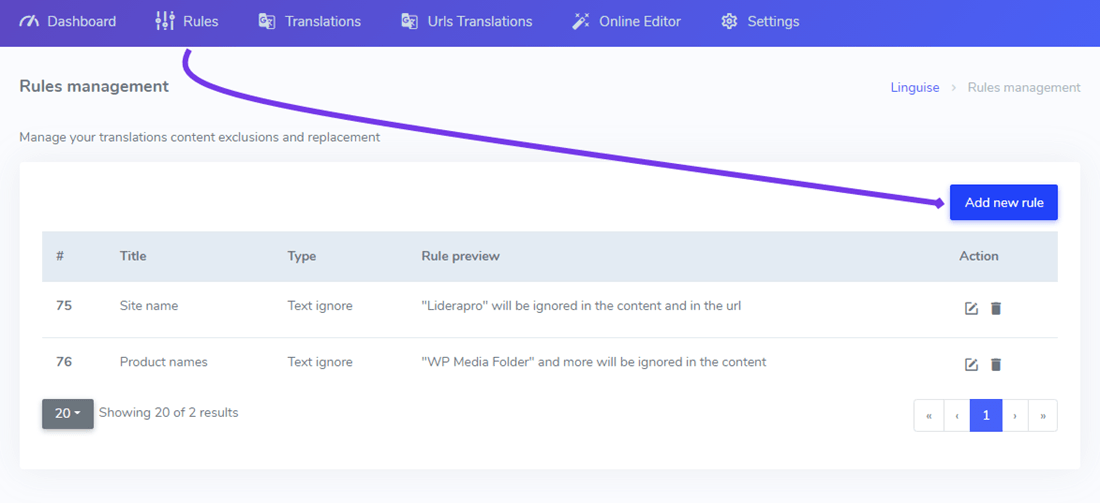
Je kunt dan de details van de tekstnegeerregel bijwerken, met name:
- De tekst die u wilt uitsluiten
- De voorwaarden voor het uitsluiten van de tekst
- De titel van de regel (alleen voor jou zichtbaar in Linguise dashboard)
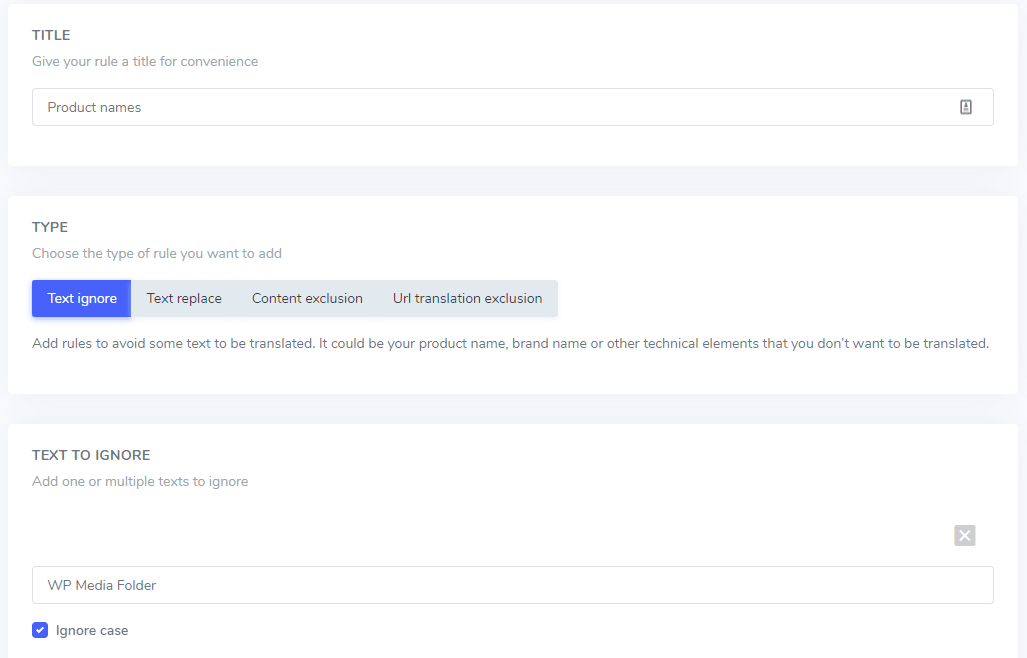
In het veld 'Tekst om te negeren' kunt u meerdere tekstuitdrukkingen toevoegen die onder dezelfde regel moeten worden uitgesloten. Volgens ons voorbeeld ziet het scherm met meerdere uitgesloten merknamen er als volgt uit:
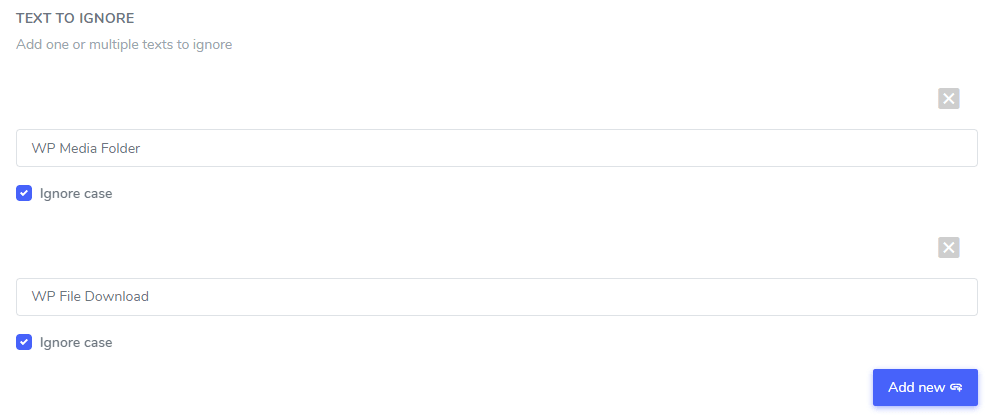
Negeer de hoofdlettergevoeligheid: de tekstinvoer is hoofdlettergevoelig, wat betekent dat als het selectievakje is aangevinkt, de regel hoofdletters en kleine letters als hetzelfde interpreteert . Voorbeeld van een vertaaluitsluiting: " Prime Video player" en " prime video player" worden beide uitgesloten als de hoofdlettergevoeligheid niet is geactiveerd .
Negeer tekst via URL's
Zodra je hebt ingesteld welke tekst je wilt negeren bij de vertaling, kun je die tekst uitsluiten voor alle URL's van je website (met de optie 'ALLE URL's') of voor URL's van specifieke pagina's.
- Oorspronkelijke URL / Vertaalde URL: Negeer de tekst van de vertaling op een specifieke URL in de oorspronkelijke taal of op een specifieke URL in een vertaalde taal.
- Jokerteken / Reguliere expressie: Negeer de tekst van de vertaling op een specifieke URL met behulp van een jokerteken of reguliere expressie.
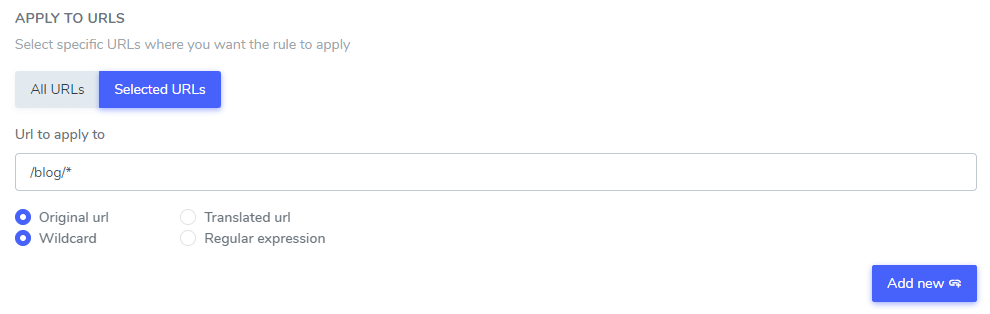
In dit voorbeeld worden “Netflix-speler”, “PrimeVideo-speler” en “YouTube-speler” uitgesloten van de vertaling in ALLE website-URL's die beginnen met www.domein.com/blog/.
Er kunnen verschillende URL-voorwaarden worden gecombineerd om bijvoorbeeld URL's in meerdere vertaalde talen te dekken.
Patroonherkenning met reguliere expressies
Het gebruik van reguliere expressies ( RegEx ) vereist enige kennis van de syntaxis en de bijbehorende . Reguliere expressies hebben een verschillende syntaxis voor URL's en woorden.
Hoewel wildcards gemakkelijker te begrijpen en te gebruiken zijn voor eenvoudige taken, biedt reguliere expressies geavanceerdere en flexibelere mogelijkheden voor patroonherkenning.
Hier volgen enkele veelvoorkomende voorbeelden van woordovereenkomstpatronen in reguliere expressies:
- Vind elk woord dat begint met "Light":
RegEx: Light\w
Uitleg: Vindt elk woord dat begint met "Light" gevolgd door nul of meer woordtekens (\w). Dit kan bijvoorbeeld "Light", "Lightbulb", "Lightweight", enz. zijn. - Vind elk woord dat eindigt op "Light":
RegEx: \w*Light
Uitleg: Vindt elk woord dat eindigt op "Light" en voorafgegaan wordt door nul of meer woordtekens. Dit kan bijvoorbeeld "Sunlight", "Daylight", "Spotlight", enz. zijn. - Zoek naar " Linguise " als geheel woord:
RegEx: \b Linguise \b
Uitleg: Deze code komt overeen met elke tekenreeks die exact bestaat uit de tekens " Linguise ". Dit zorgt er ook voor dat er geen overeenkomsten zijn met andere woorden zoals Linguise App", maar alleen met " Linguise ".
Meer informatie over reguliere expressies vind je hier: https://www.regular-expressions.info/
Als je hierover twijfelt, raden we aan om wildcards in plaats van reguliere expressies.
Mocht je vragen hebben, neem dan gerust contact met ons op via het contactformulier!
Negeer tekst op basis van taal
De tekst die je hebt toegevoegd, kan alleen in een specifieke taal of in alle talen worden uitgesloten. Dit is erg handig, omdat sommige woorden in verschillende talen hetzelfde gespeld kunnen worden, maar slechts in één taal hoeven te worden uitgesloten. Het woord 'ilimitados' is bijvoorbeeld hetzelfde in het Portugees en in het Spaans.
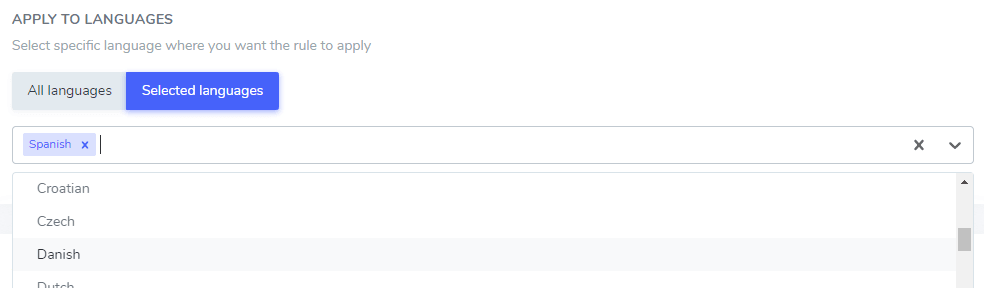
In dit voorbeeld worden “Netflix-speler”, “PrimeVideo-speler” en “YouTube-speler” alleen in het Spaans uit de vertaling weggelaten.
Negeer tekst in HTML-inhoud
De tekst die je hebt toegevoegd, kan worden uitgesloten van een deel van je HTML-inhoud met behulp van een of meerdere CSS-selectors. Gebruik de code-inspector van je browser om een CSS-selector te vinden en deze als volgt toe te voegen.
Een CSS-selector verkrijgen:

En voeg het toe aan de regelinstellingen:
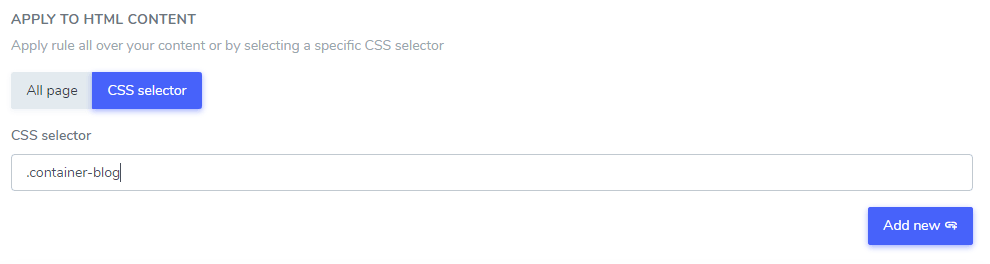
In dit voorbeeld worden “Netflix-speler”, “PrimeVideo-speler” en “YouTube-speler” alleen uitgesloten van de vertaling in de HTML-inhoud die in de CSS-selector .blog staat.
Negeer tekst in URL-inhoud
De tekst die je hebt toegevoegd, kan worden weggelaten uit de URL zelf. Dit betekent dat 'PrimeVideo player' in URL's ongewijzigd blijft. Bijvoorbeeld: 'www.domain.com/prime-video-player' wordt niet vertaald.

URL-aanpassing: let op configuraties die URL's op live websitecontent wijzigen. Dit kan leiden tot 404-foutmeldingen die u moet omleiden.
Sluit inhoudsvertaling uit met behulp van een tag
Je kunt overal in je HTML-inhoud een tag toevoegen die je wilt uitsluiten van vertaling: translate=”no”
Alle inhoud binnen de HTML-container, inclusief alle subelementen, wordt NIET vertaald.
HTML-uitsluiting op basis van een tag (voorbeeld):
<div translate=”no”>
<p>Deze tekst wordt helemaal niet vertaald.</p>
</div>