

Spis Treści
Dodaj tekst do zignorowania
Reguła ignorowania tekstu pozwala uniknąć tłumaczenia pewnego tekstu, jeśli spełnione zostaną określone przez Ciebie warunki.
To zazwyczaj pierwszy typ reguły, który dodasz do tłumaczenia swojej witryny, aby wykluczyć na przykład nazwę produktu lub firmy. Aby dodać taką regułę, połącz się z Panel Linguise > Kliknij Reguły > Dodaj nową regułę.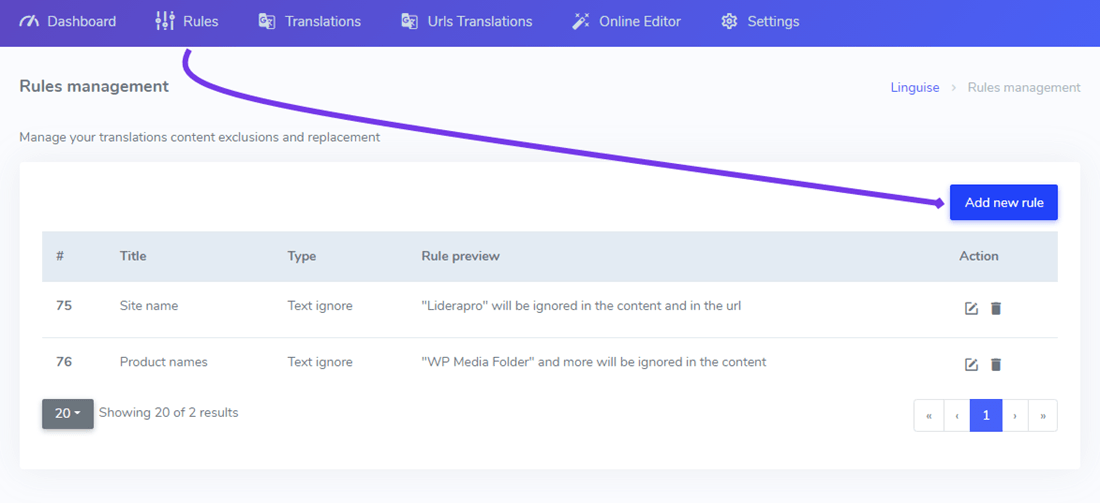
Następnie będziesz mógł zaktualizować szczegóły reguły ignorowania tekstu, głównie:
- Tekst, który chcesz wykluczyć
- Warunki wykluczenia tekstu
- Tytuł reguły (widoczny tylko dla Ciebie w panelu Linguise )
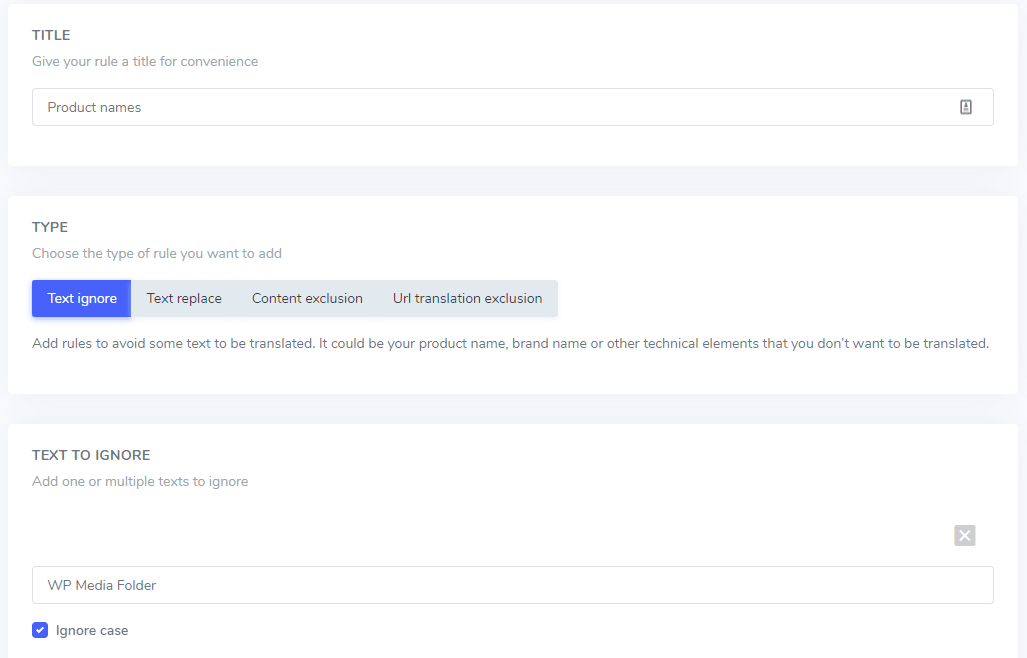
W polu Tekst do zignorowania możesz dodać kilka wyrażeń tekstowych, które mają być wykluczone w ramach tej samej reguły. Zgodnie z naszym przykładem ekran z wykluczeniami kilku nazw marek będzie wyglądał tak:
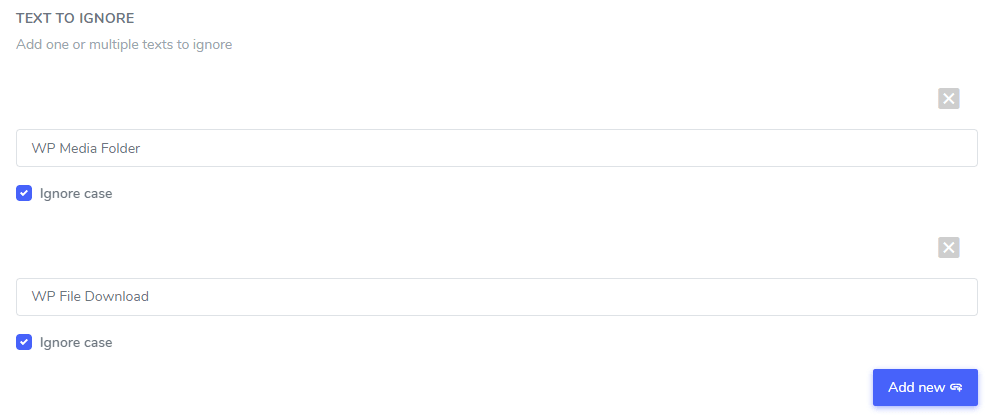
Ustawienie „Ignoruj wielkość liter”: wprowadzany tekst uwzględnia wielkość liter, co oznacza, że jeśli pole wyboru jest zaznaczone, reguła zinterpretuje wielkie i małe litery jako takie same. Przykład wykluczenia tłumaczenia: „ P rime video player” i „ p rime video player” z wyłączonym rozróżnianiem wielkości liter zostaną wykluczone.
Ignoruj tekst w adresach URL
Po skonfigurowaniu tekstu, który nie będzie uwzględniany w tłumaczeniu, możesz wykluczyć ten tekst ze wszystkich adresów URL swojej witryny (używając opcji WSZYSTKIE adresy URL) lub z adresów URL wybranych stron.
- Oryginalny adres URL / Przetłumaczony adres URL: Ignoruj tekst z tłumaczenia pod określonym adresem URL z języka oryginalnego lub z określonego adresu URL z języka przetłumaczonego
- Symbol wieloznaczny/wyrażenie regularne: zignoruj tekst z tłumaczenia pod określonym adresem URL za pomocą symbolu wieloznacznego lub wyrażenia regularnego
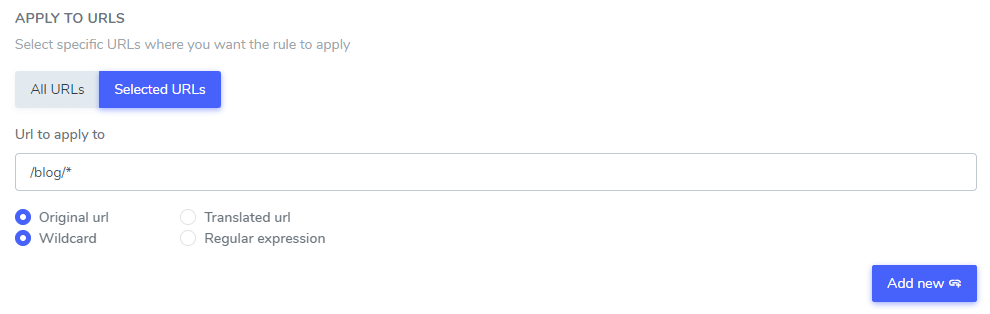
W tym przykładzie: „Netflix player”, „PrimeVideo player”, „YouTube player” zostaną wykluczone z tłumaczenia we WSZYSTKICH adresach URL witryn rozpoczynających się od www.domena.com/blog/
Można mieszać różne warunki dotyczące adresów URL, aby na przykład uwzględnić adresy URL w kilku przetłumaczonych językach.
Dopasowywanie wzorców wyrażeń regularnych
Korzystanie z wyrażeń regularnych ( RegEx ) wymaga pewnej znajomości składni i pojęć z nimi związanych . Wyrażenia regularne mają inną składnię dla adresu URL i słowa.
Podczas gdy symbole wieloznaczne są łatwiejsze do zrozumienia i użycia w przypadku prostych zadań, RegEx zapewnia bardziej zaawansowane i elastyczne możliwości dopasowywania wzorców.
Oto kilka typowych przykładów wzorca dopasowywania słów w wyrażeniu regularnym:
- Dopasuj dowolne słowo zaczynające się od „Light”:
Wyrażenie regularne: Light\w
Wyjaśnienie: Dopasowuje dowolne słowo zaczynające się od „Light”, po którym następuje zero lub więcej znaków (\w). Może to pasować do słów „Light”, „Lightbulb”, „Lightweight” itd. - Dopasuj dowolne słowo kończące się na „Light”:
Wyrażenie regularne: \w*Light
Wyjaśnienie: Dopasowuje dowolne słowo kończące się na „Light” poprzedzone zerem lub większą liczbą znaków. Może to pasować do słów „Sunlight”, „Daylight”, „Spotlight” itd. - Dopasuj „ Linguise ” jako całe słowo:
Wyrażenie regularne: \b Linguise \b
Wyjaśnienie: To dopasuje dowolny ciąg składający się dokładnie ze znaków słowa „ Linguise ”. Zagwarantuje to również, że nie będzie on pasował do innych słów, takich jak Linguise App, a jedynie do „ Linguise ”.
Więcej szczegółów na temat wyrażeń regularnych można znaleźć tutaj: https://www.regular-expressions.info/
Jeśli masz wątpliwości, zalecamy używanie symbolu wieloznacznego zamiast wyrażenia regularnego.
W razie jakichkolwiek wątpliwości zawsze możesz się z nami skontaktować, wypełniając formularz kontaktowy!
Ignoruj tekst według języka
Dodany tekst do ignorowania można wykluczyć tylko w wybranym języku lub we wszystkich językach. Jest to bardzo przydatne, ponieważ niektóre słowa mogą mieć tę samą pisownię w różnych językach, ale wymagają wykluczenia tylko w jednym. Na przykład słowo „ilimitados” brzmi tak samo w języku portugalskim i hiszpańskim.
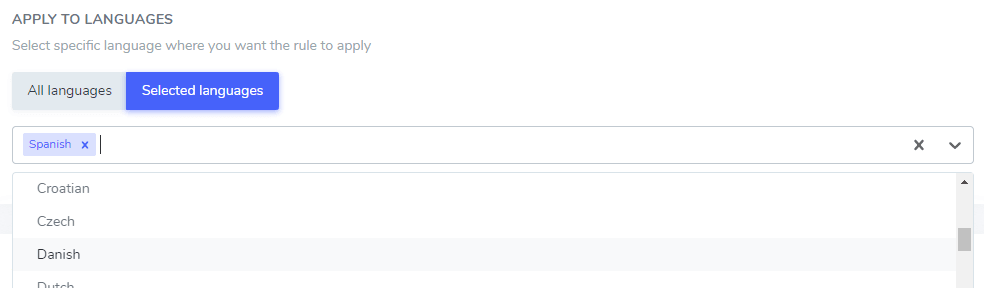
W tym przykładzie: „Netflix player”, „PrimeVideo player”, „YouTube player” zostaną wykluczone z tłumaczenia tylko na język hiszpański.
Ignoruj tekst w treści HTML
Dodany tekst można pominąć, wykluczając go z części zawartości HTML za pomocą jednego lub kilku selektorów CSS. Korzystając z inspektora kodu przeglądarki, możesz pobrać dowolny selektor CSS i dodać go jako następny.
Pobierz selektor CSS:

I dodaj to w ustawieniach reguły:
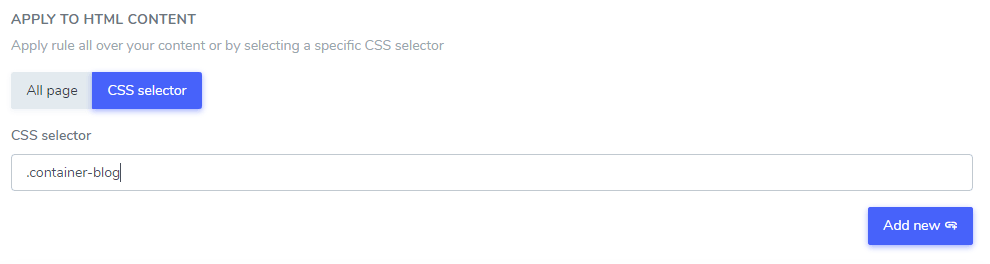
W tym przykładzie: „Odtwarzacz Netflix”, „Odtwarzacz PrimeVideo”, „Odtwarzacz YouTube” zostaną wykluczone z tłumaczenia tylko w treści HTML znajdującej się w selektorze CSS .blog
Ignoruj tekst w treści adresów URL
Dodany tekst można pominąć w samym adresie URL, co oznacza, że „PrimeVideo player” pozostanie niezmieniony w adresach URL. Na przykład: „www.domena.com/prime-video-player” nie zostanie przetłumaczony.

Modyfikacja adresu URL: uważaj na konfigurację, która modyfikuje adresy URL w aktywnej treści witryny. Może to powodować błąd 404, który należy przekierować.
Wyklucz tłumaczenie treści za pomocą znacznika
Możesz umieścić w dowolnym miejscu treści HTML znacznik, który wykluczy ją z tłumaczenia: translate=”no”
Cała zawartość znajdująca się w kontenerze HTML NIE zostanie przetłumaczona, łącznie ze wszystkimi podelementami.
Przykład wykluczenia HTML według znacznika:
<div translate=”no”>
<p>Ten tekst w ogóle nie będzie tłumaczony</p>
</div>