Cuprins
Ce este HTML-ul inline?
Elementele inline sunt cele care ocupă doar spațiul delimitat de etichetele HTML care definesc elementul, în loc să întrerupă fluxul conținutului.
Elementele HTML inline sunt de obicei folosite pentru a adăuga un anumit conținut în interiorul unei etichete HTML. De exemplu, în interiorul unui paragraf de text (un<p> etichetă) puteți face o parte din acest text îngroșată adăugând o <strong>etichetă sau puteți adăuga un hyperlink cu o <a>etichetă. Acesta este cel mai frecvent conținut HTML inline, dar poate fi și pictograme de font sau <span>pentru stilizare personalizată.</span></a></strong>.
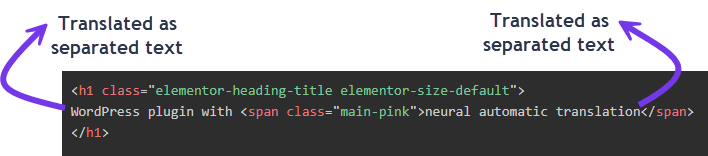
Iată o <span>etichetă în interiorul titlului secțiunii 1:</span>
<h1 class="elementor-heading-title elementor-size-default">
WordPress plugin with <span class="main-pink">neural automatic translation</span>
</h1>
Conținutul HTML inline este considerat complicat de gestionat de instrumentele de traducere automată. În mod implicit, este regrupat ca o propoziție individuală, pentru a păstra contextul conținutului, apoi tradus și regrupat în diverse moduri, în funcție de limbă.
Puteți schimba acest comportament cu regula de traducere HTML „Ignoră fișierul inline”.
Regula de ignorare a HTML-ului inline
Regula de traducere HTML „ignorare inline” este o regulă globală care evită ca eticheta HTML să fie considerată o singură etichetă, dar păstrează fiecare element inline și le traduce separat.
Cum este asta interesant?
De obicei, având în vedere potențiala pierdere a calității traducerii, nu este așa, dar această regulă este folosită în principal pentru a evita conflictele cu conținut inline foarte exotic.
Pentru a adăuga o astfel de regulă, conectați-vă la tabloul de bord Linguise > faceți clic pe Reguli > Adăugați o regulă nouă.
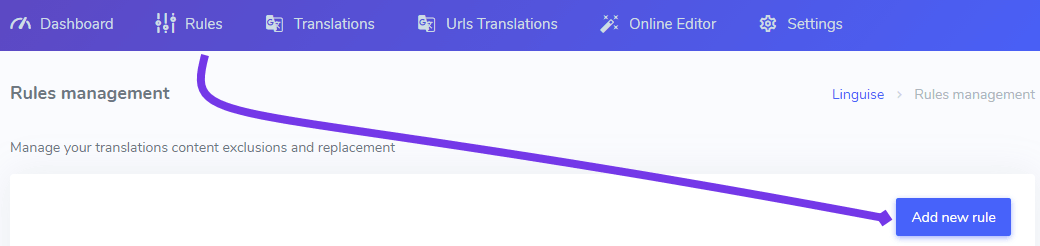
Veți putea apoi să adăugați detaliile de înlocuire, în principal:
- Titlul regulii (vizibil numai de dvs. în tabloul de bord Linguise )
- Adresa URL unde doriți să aplicați excluderea traducerii inline
- Selecția limbilor pentru aplicarea excluderii
- Un selector CSS specific pentru aplicarea excluderii